07 / 11
성능 관리
모델 버전 관리 및 비교, 성능 측정, 400개/100개 테스트 결과
MLflow — PaddleOCR 성능 추적
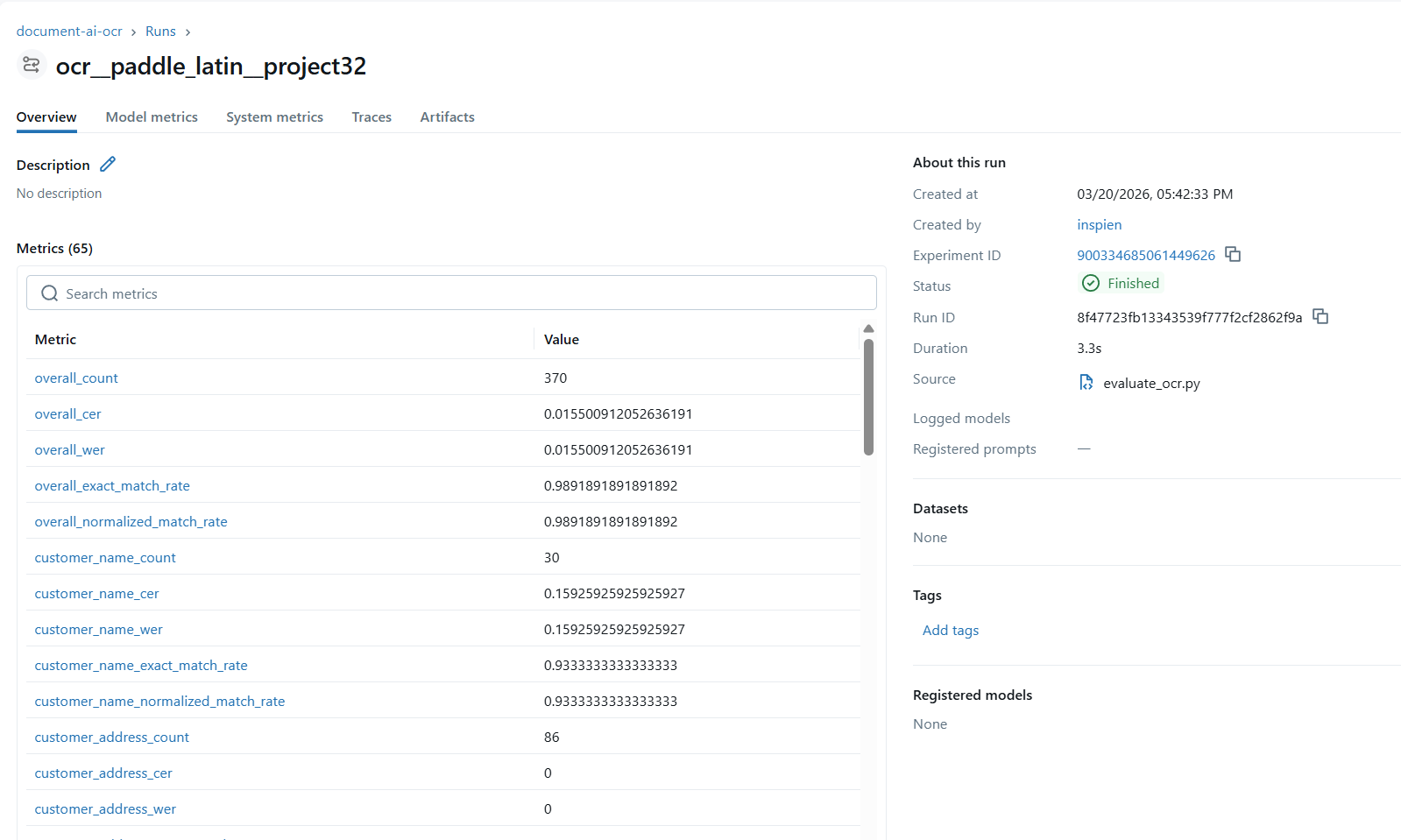
PaddleOCR 성능 추적 — CER/WER/EM 지표
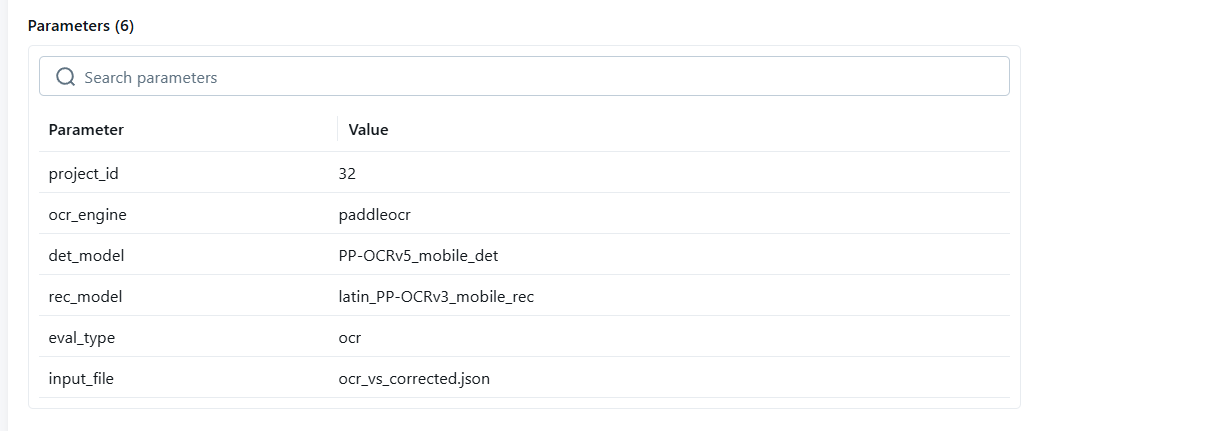
PaddleOCR 필드별 성능 상세
MLflow — LayoutLM (KIE) 성능 추적
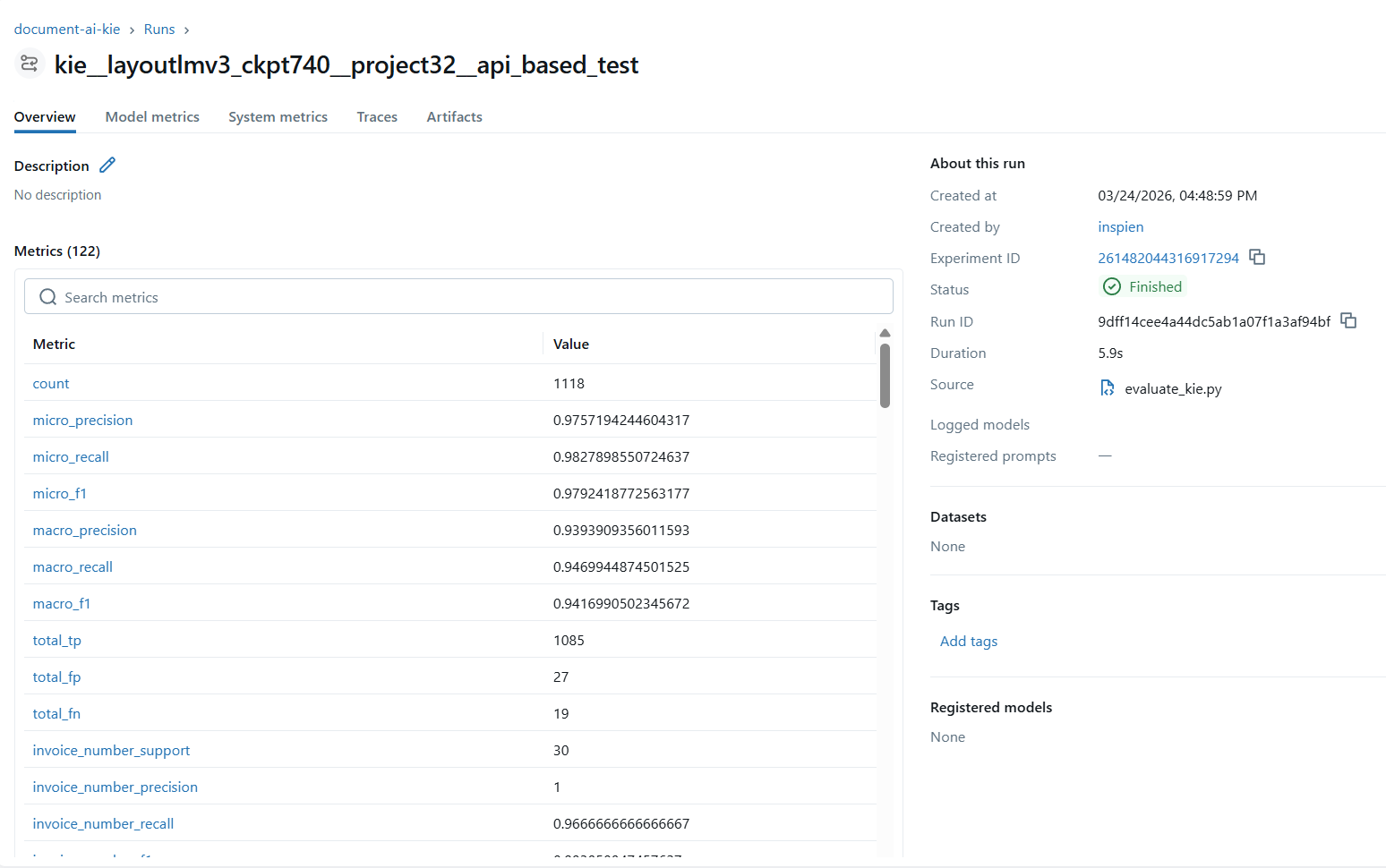
LayoutLM KIE 성능 추적 — Precision/Recall/F1
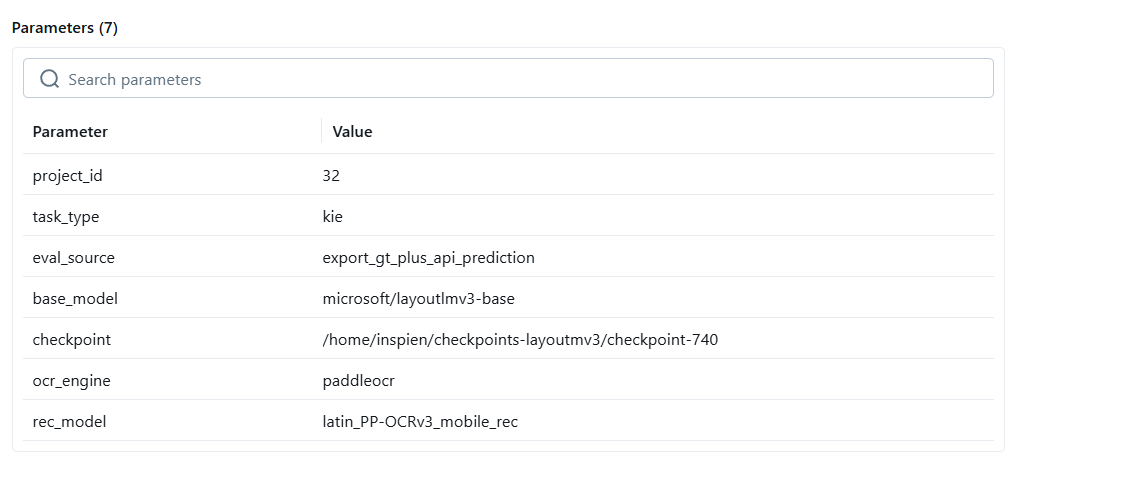
LayoutLM KIE 라벨별 성능 상세
성능 지표 구분: 모델 내부 평가 vs 자체 운영 테스트
Document AI 파이프라인의 성능은 두 가지 관점에서 측정됩니다. 모델 학습 시 자동으로 산출되는 내부 평가 지표와, 실제 운영 문서를 대상으로 직접 측정한 자체 테스트 지표입니다.
모델 내부 평가 (HuggingFace Trainer)
학습 완료 후 Trainer.evaluate()가 test split에 대해 자동 산출. seqeval 라이브러리 기반 token-level 평가.
checkpoint-740 기준. 학습에 사용하지 않은 데이터로 평가.
자체 운영 테스트 (MLflow 기록)
실제 운영 환경의 문서를 대상으로 end-to-end 파이프라인(OCR → 추론 → 후처리)을 거쳐 필드 단위로 직접 측정. MLflow에 실험 결과를 기록하여 추적.
실제 운영 문서 기준. OCR → 추론 → 후처리 전체 파이프라인 포함.
두 지표의 차이
모델 내부 평가는 token-level에서 측정. OCR 오류는 반영되지 않고, 모델 자체의 분류 성능만 평가.
자체 운영 테스트는 필드 단위(end-to-end)에서 측정. OCR 오류, 후처리 로직, 실제 문서 다양성이 모두 반영된 실전 성능.
두 지표 모두 MLflow에 기록하여 checkpoint별 성능 이력을 추적하고, 모델 배포 판단 근거로 활용.