Project
AI Document Processing Pipeline
인보이스 및 물류 문서에서 구조화된 데이터를 자동 추출하는 end-to-end AI 문서 처리 파이프라인. PaddleOCR + LayoutLM 기반 배치 추론, MLflow 실험 추적, S3 권한 분리 및 다층 백업 체계, 한글 문서 확장까지 PoC에서 운영 단계로의 전환을 포함합니다.
Service Screenshots
프로젝트 TASK 리스트
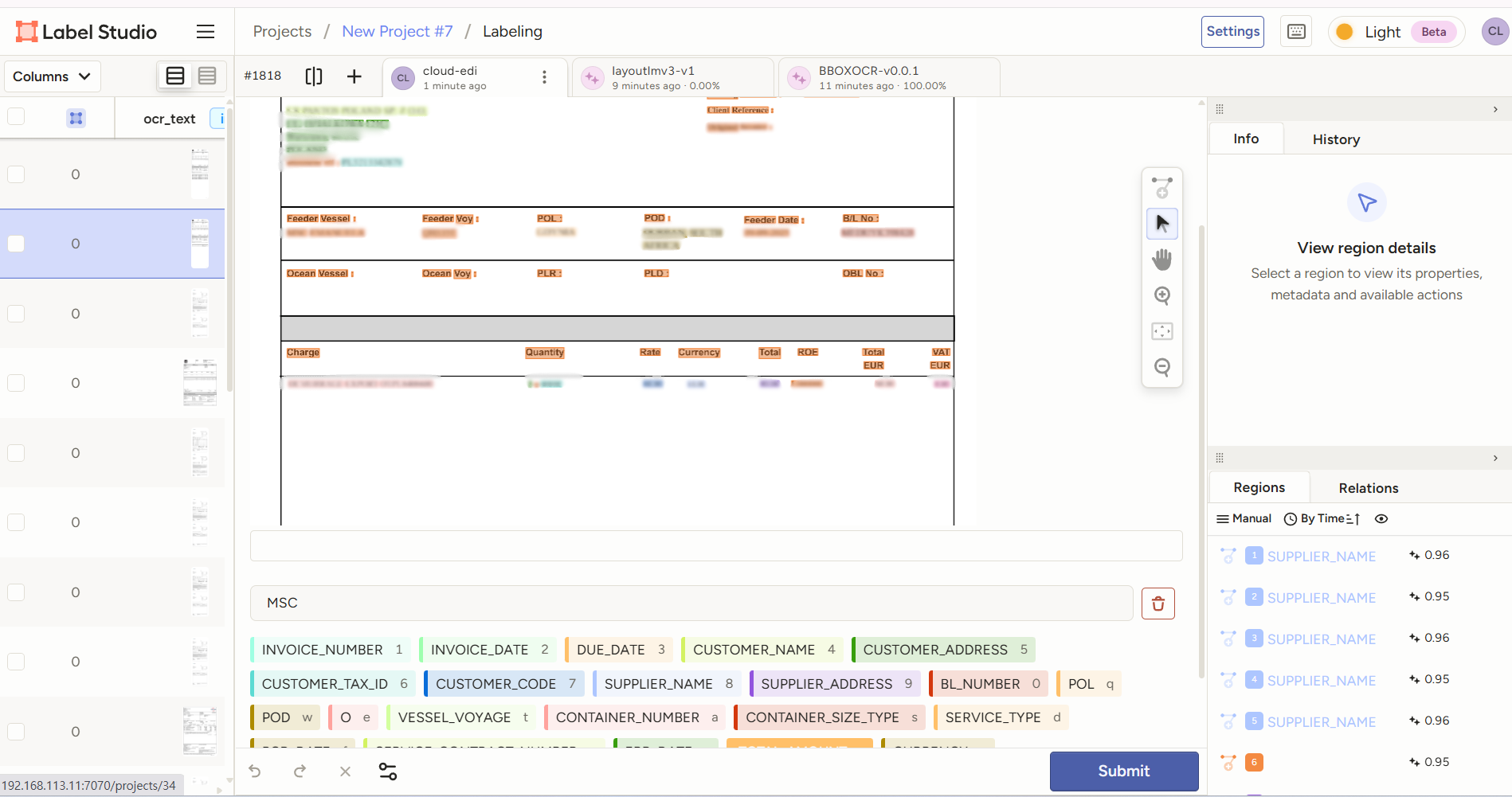
Document AI 검수 화면
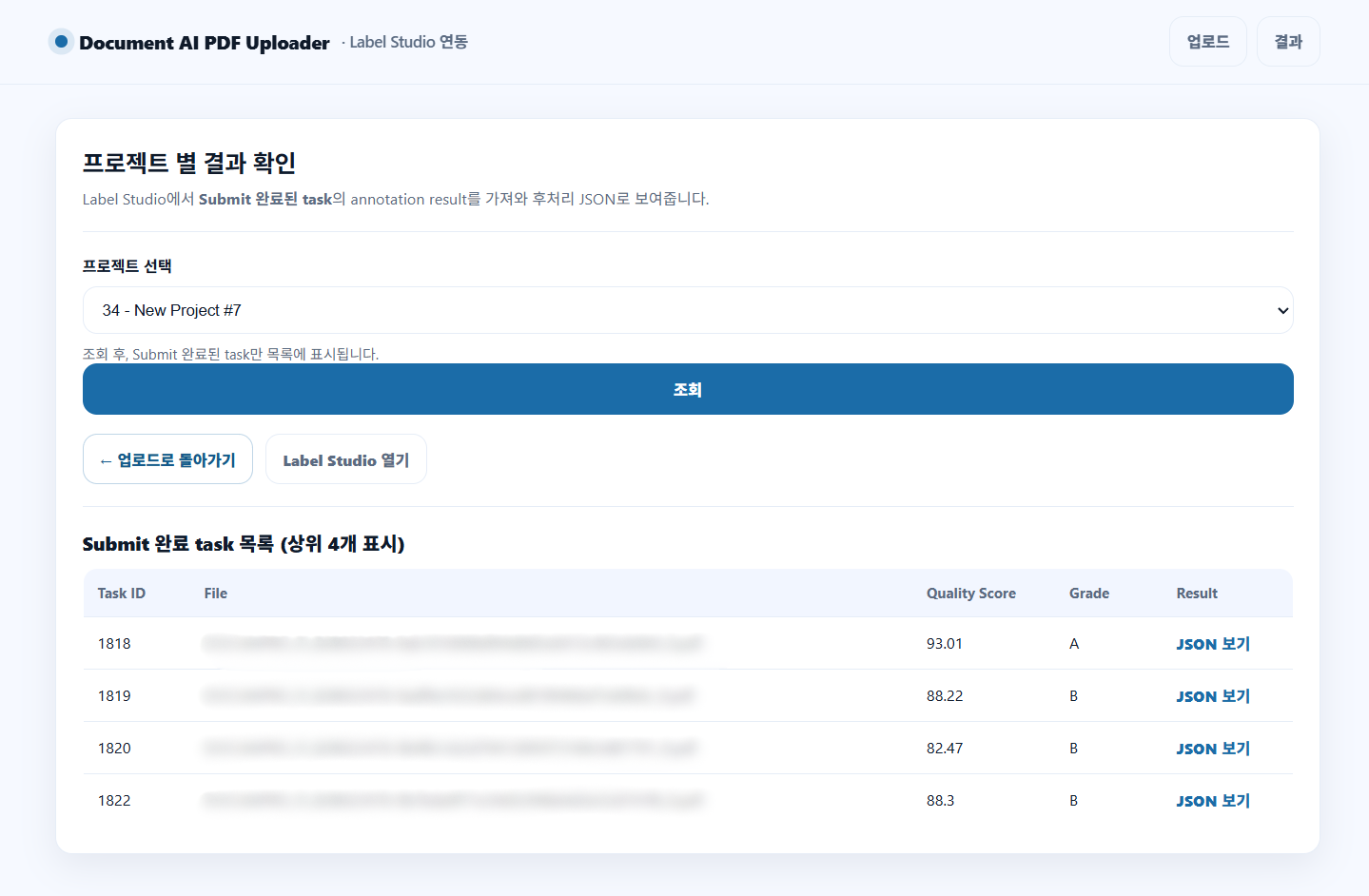
Document AI 추출 결과
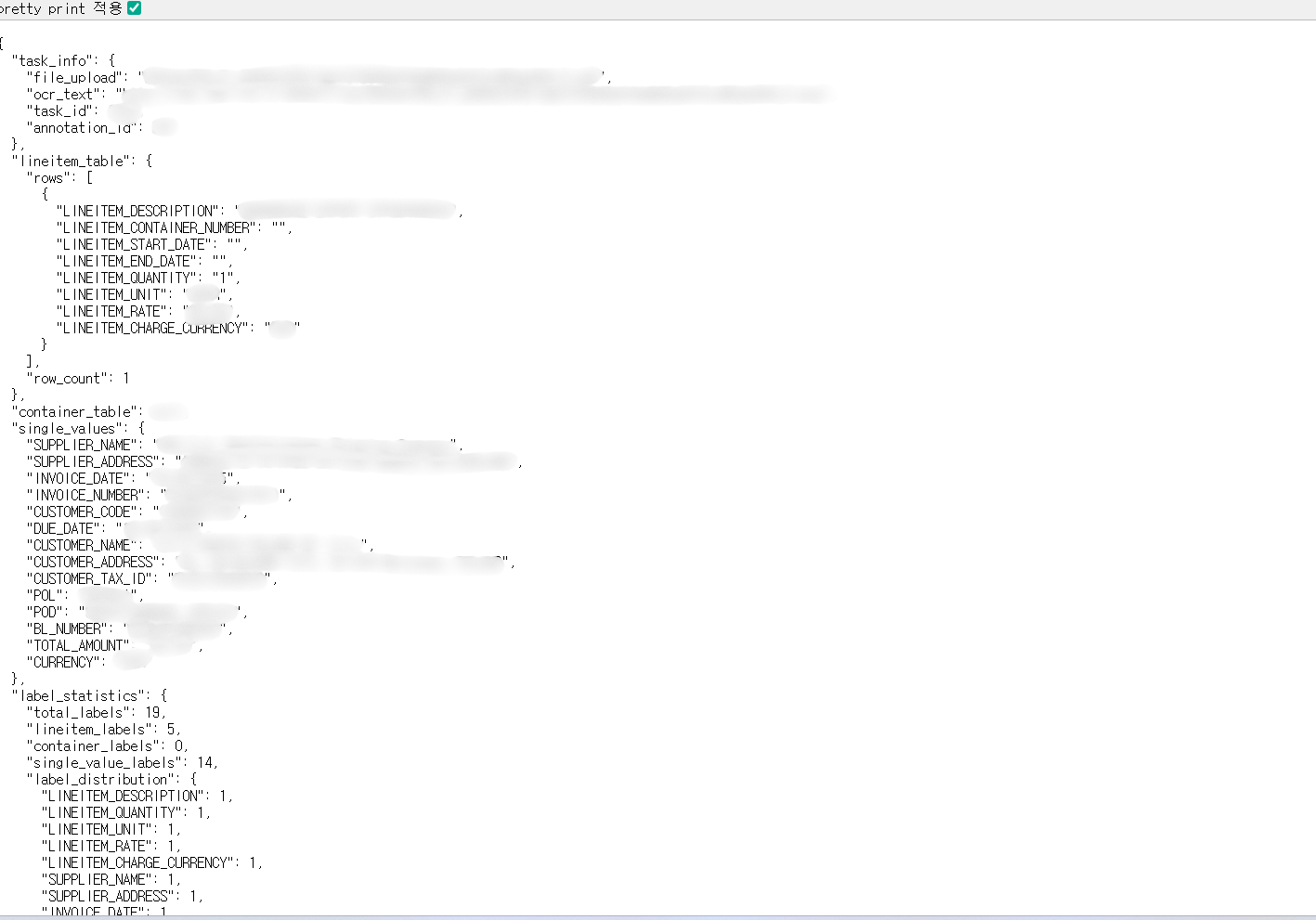
Document AI 추출 결과 상세
95.4%
F1 Score
BIO 태깅 적용 기준
80%↑
업무 효율성
수작업 대비 처리 시간 단축
89
추출 라벨 수
BIO 태깅 (B-/I-) 포함
98.7%
토큰 정확도
eval_accuracy 기준
Pipeline Flow
01
개요
아키텍처 및 구현 목표, 프로젝트 전체 구조
02
환경 구성
Label Studio + EasyOCR + LLM 환경 구성, Cloud/On-premise, 필요 자원
03
OCR 파이프라인
PDF → Label Studio → EasyOCR Backend → 텍스트/박스 추출, API 토큰 적용
04
모델 학습
데이터 수집-정제-학습-검증-배포 파이프라인, 추가 학습, checkpoint 관리
05
모델 / 데이터 처리
모델 비교, Token 추출, INPUT 분류, 전처리/후처리 코드, S3 연결
06
LayoutLM 분석
sub-token 처리, Invoice 공통 필드 추출, 성능 지표 분석
07
성능 관리
모델 버전 관리 및 비교, 성능 측정, 400개/100개 테스트 결과
08
배포 & 운영
Tesseract/LayoutLM 배치, 한글 문서 적용, S3 권한, 백업
09
PaddleOCR 도입
PaddleOCR 도입 배경, 학습 구조, 환경 설정, 교체 전략, 배치 추론
10
BIO 라벨 & 학습 개선
B-I-O 태깅 도입, Classifier Head 확장, 행 경계 학습, 학습 결과 검증
11
문제 해결
OCR 추출 문제, Token 제한 이슈, 예외 케이스 처리
Tech Stack