01 / 11
개요
아키텍처 및 구현 목표, 프로젝트 전체 구조
필요 자원
학습 용 인스턴스
GPU 서버 1대
모델 Fine-tuning 및 추가 학습 수행
추론 용 인스턴스
CPU 서버 1대
GPU 불필요, 실시간 추론 서빙
비용 최적화 전략
- •GPU 인스턴스 상시 운영 시 비용 부담 (최소 시간당 약 700원, ml.g4dn.xlarge 기준)
- •실시간 학습이 필요한 경우 특정 시간대(예: 오후 1~3시)에만 서비스 가동
- •정기 학습의 경우 하루 1회 또는 주 1회 스케줄링으로 비용 절감
아키텍처
Cloud 환경
AWS SageMaker GPU 서버에서 LayoutLM 학습, checkpoint를 S3에 저장. Label Studio와 EasyOCR Backend는 ECS 컨테이너로 운영.
On-premise 환경
사내 GPU 서버에서 LayoutLM 학습, checkpoint 로컬 저장. Label Studio와 EasyOCR Backend는 동일 서버 또는 별도 서버에서 Docker로 운영.
초기 학습 파이프라인
Tesseract / EasyOCR 기반으로 토큰 추출 (Label Studio ML Backend)
Label Studio에서 필드별로 파싱하여 학습 데이터 생성
LayoutLM에서 학습 진행
테스트 데이터 기반 성능 테스트
학습된 모델 데이터를 S3에 저장
추가 학습 (재학습) 파이프라인
S3로부터 Label Studio에서 사용자가 수정한 추가 데이터 (Tesseract 기반 TOKEN) 불러오기
LayoutLM에서 추가 학습 진행
테스트 데이터 기반 성능 테스트
학습된 모델 데이터를 S3에 저장
추론 + 검수 파이프라인
사용자가 PDF 업로드 (S3 직접 업로드 또는 연계 서비스)
전처리 진행 (PDF → PNG 변환, 해상도 조정)
Tesseract OCR → 토큰 + bbox 추출
LayoutLM으로 각 토큰에 INVOICE_NUMBER, CUSTOMER_NAME 등 라벨 예측
Label Studio 화면에서 토큰 박스 + LayoutLM 예측 라벨이 미리 표시된 상태로 검수/수정
수정된 데이터를 S3로 전달
S3에 저장된 데이터를 불러와 LayoutLM 재학습 진행
→ 핵심: OCR 토큰 + LayoutLM 라벨을 한 화면에서 다루는 것이 목표. 사람이 검수/수정한 결과가 다시 학습 데이터로 순환되는 Human-in-the-Loop 구조.
구현 목표
인보이스 타입별 분류
다양한 포맷의 인보이스를 자동으로 타입 분류
재학습 간소화
검수 데이터 기반 재학습 파이프라인 자동화
검증 프로세스
학습 결과에 대한 체계적인 성능 검증 과정
아키텍처 (기술적 관점)
LayoutLM 핵심 기술 요소
1. 의미론적 텍스트 임베딩
텍스트 임베딩을 사용하여 의미론적 의미를 기반으로 키-값 쌍을 포착. 텍스트의 내용과 맥락을 이해하고 키-값 쌍 내 관계를 인식하는 능력.
비슷한 문맥에서 쓰이는 단어들은 비슷한 방향으로 gradient를 받아 벡터 공간에서 가까운 위치로 수렴. 예: "Invoice No."와 "No. Factura"는 임베딩 공간에서 유사한 위치에 배치됨.
2. 2D 레이아웃 이해
좌표를 기반으로 텍스트 요소의 2D 위치를 파악하여 키-값 쌍을 추출. 보통 키와 해당 값은 문서 레이아웃 내에서 상대적으로 가까운 거리에 위치하기 때문에 공간 정보가 핵심.
3. 시각적 특징
글꼴 크기, 굵기 등 시각적 특징을 통합하여 키-값 쌍 예측 정확도 향상.
LayoutLM SER & RE
SER (Semantic Entity Recognition)
BIOES 레이블 체계를 사용하여 각 토큰에 의미 태그를 부여. B(Beginning), I(Inside), O(Outside), E(End), S(Start) 레이블로 엔티티 경계를 식별. ANSWER, QUESTION, HEADER 등의 엔티티 타입 분류.
RE (Relation Extraction)
SER에서 생성된 예측을 기반으로 키-값 관계를 추출. 키-값 쌍이 유효하면 1, 아니면 0을 출력하는 분류기 역할. 테이블 구조, key-value가 멀리 떨어진 경우 등 복잡한 레이아웃에서 필수.
⚠ LayoutLM v2, v3 / LayoutXLM의 RE 모델은 상업적 사용 불가 — 라이선스 제약 고려 필요
Document AI
Step Guide
운영 환경
서버
- OS: Rocky Linux 8.10
- CPU: Intel Xeon E5-2630 v3 (8코어 × 2소켓, 물리 16코어 / 논리 32코어)
- 메모리: 125GB
- 용도: 테스트 및 PoC 환경
사용 도구
LayoutLM (AI 모델)
문서 이미지(PDF → PNG)와 OCR 텍스트 정보를 함께 입력받아 문서 내 주요 필드(Invoice No, Date, Amount 등)를 자동으로 분류 및 추출하는 AI 모델.
Tesseract OCR을 통해 문서 이미지에서 텍스트와 Bounding Box 정보를 추출
해당 정보를 Label Studio Task 데이터로 저장
LayoutLM 모델이 OCR 결과를 기반으로 필드 라벨을 예측
예측 결과를 Label Studio Prediction 형태로 등록
→ 목적: 사람이 수행하던 문서 판독 및 데이터 입력 작업을 자동화하고, 학습을 통해 정확도를 지속적으로 개선
Label Studio (오픈소스 라벨링 도구)
문서 이미지 위에 Bounding Box 기반 라벨을 지정하고 검수(QA)를 수행하는 도구.
- • OCR 결과 기반 Task 생성
- • LayoutLM 모델의 Prediction 결과 확인
- • 사용자가 추론 결과 검수 및 수정
- • Submit된 데이터를 학습 데이터로 활용
→ 목적: 정확한 라벨 데이터 구축, 모델 추론 결과 검수 및 보정, 학습 데이터 품질 관리
PDF Uploader (내부 웹 애플리케이션)
사용자가 PDF 파일을 업로드하면 전처리부터 Task 생성까지 자동으로 수행하는 Ingestion Layer.
PDF 업로드
PDF → PNG 전처리
전처리된 이미지 저장
Label Studio Task 자동 생성
→ 목적: 문서 업로드 및 전처리 자동화, 라벨링/검수 워크플로우를 일관된 방식으로 운영
시스템 처리 흐름
PDF Uploader를 통해 문서 업로드
PDF → PNG 전처리
Tesseract OCR (텍스트 + Bounding Box 추출)
Label Studio Task 생성
LayoutLM 모델 추론 (Prediction 생성)
Label Studio에서 검수 (QA)
학습 데이터 축적 및 모델 개선
파일 업로드 방식 (상용화 고려)
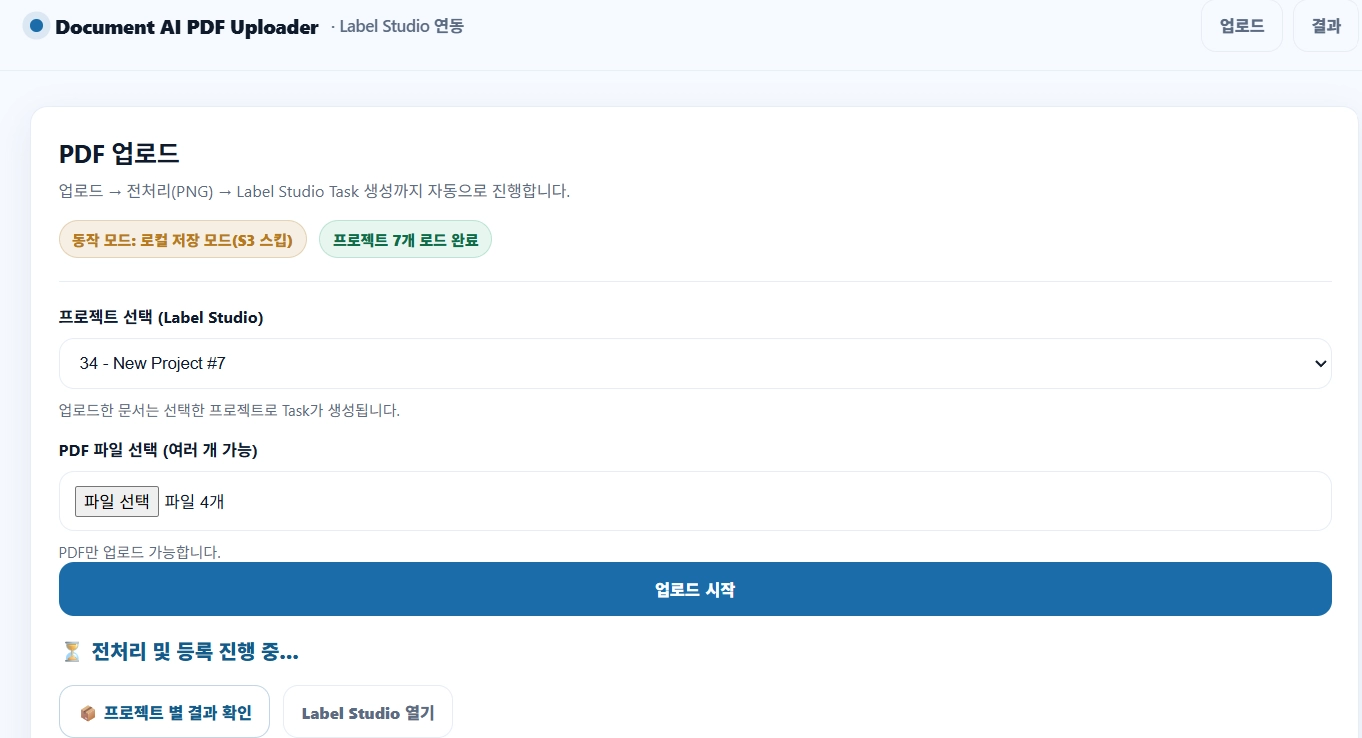
UI 기반 업로드
사용자가 웹 UI를 통해 직접 PDF 파일을 업로드. 기존 연계 서비스와 통합하여 운영 가능.
이메일 기반 업로드
지정된 이메일 주소로 Invoice PDF를 전달하면 자동으로 S3에 저장 후 파이프라인으로 전달. 별도 시스템 접속 없이 이메일 전송만으로 문서 처리 요청 가능.
고객사의 운영 환경(Cloud / On-premise)에 따라 유연하게 적용 가능
검수 (QA) 프로세스
품질 지표
각 Task에는 quality_score, quality_grade, quality_missing_str 등의 품질 지표가 표시됨. 이를 참고하여 수정이 필요한 Task만 선별하여 검수 진행.
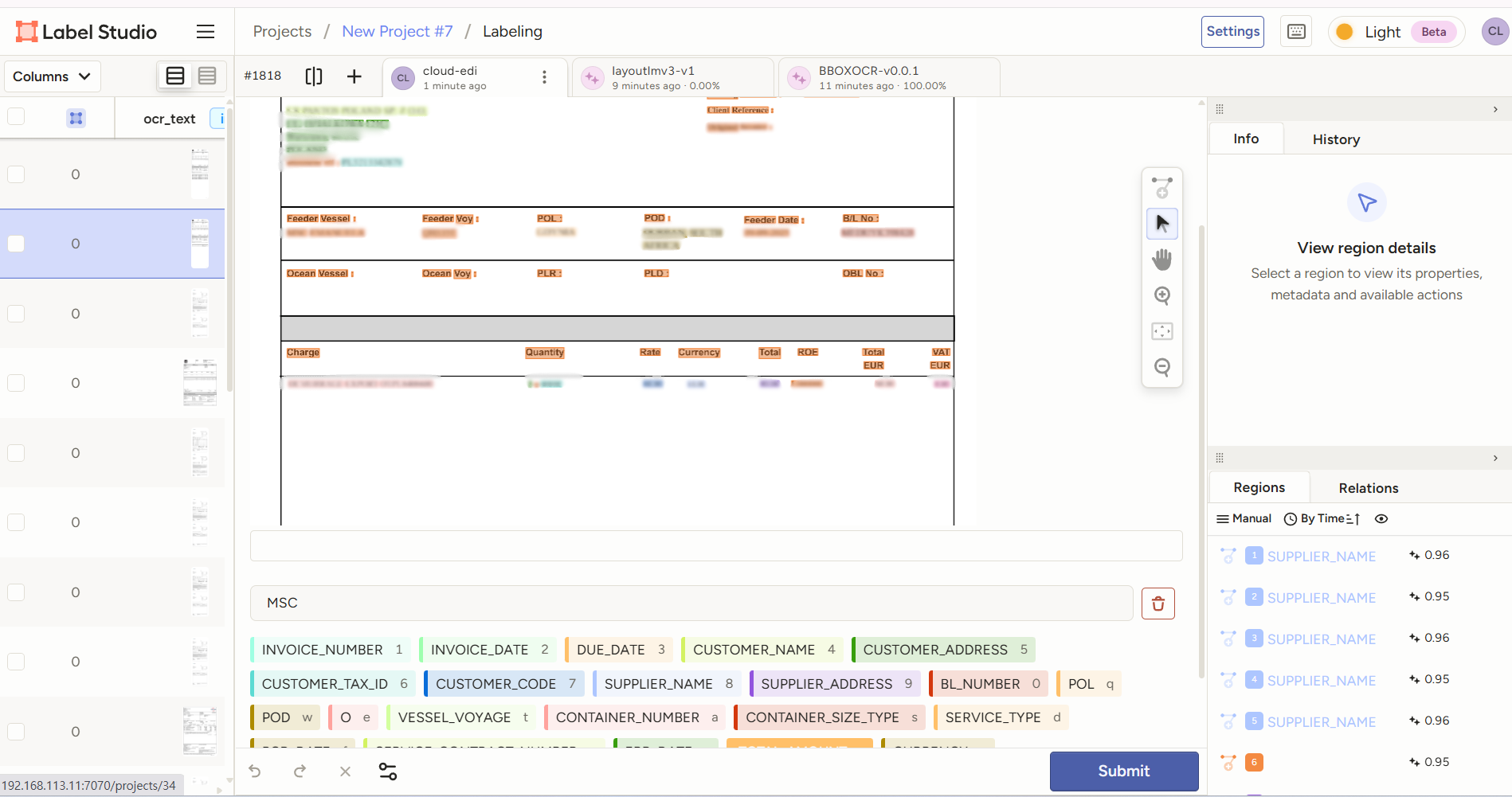
검수 화면 구성
LayoutLM 모델이 예측한 라벨이 텍스트별로 미리 적용된 상태로 표시. 사용자는 수정이 필요한 부분만 검수하면 됨.
검수 시 확인 사항: (1) 텍스트에 올바른 Label이 매칭되어 있는지 (2) 필수 Label 중 누락된 값이 없는지
처리 성능
현재 기준 10개 문서 처리에 약 1분~1분 30초 소요. 향후 추가 최적화를 통해 단축 예정.
추출 대상 라벨 목록
새로운 라벨 추가 시 해당 라벨에 대한 모델 추가 학습이 필요
PoC 제약사항
Token Length Limitation
LayoutLM 모델의 입력 토큰 길이 제한(max_length = 512)으로 인해 텍스트 양이 많은 문서(특히 Line Item이 많은 Invoice)의 경우 문서 후반부 영역이 truncation되어 일부 Line Item 추론이 누락될 수 있음.
→ 개선 계획: Sliding Window(Chunk 기반 추론) 방식을 적용하여 문서를 여러 구간으로 나누어 추론 후 결과를 병합
학습 과정
Task별 검수가 완료된 프로젝트의 경우, Label Studio에서 Submit 처리된 Annotation 데이터를 학습 데이터로 활용. 새로운 Invoice 문서 유형이 추가되는 경우, 기존 Base Model(LayoutLM)을 기반으로 추가 학습(Fine-tuning)을 진행하여 새로운 모델을 생성.
- • 문서 유형별 특성을 반영한 특화 모델(Specialized Model) 구축
- • 문서 데이터 추출 정확도 지속적 개선
모델 특화 전략 (예정)
기존 Base 모델이 비용 중심 Invoice에 특화되어 있는 반면, 날짜 및 기간이 중심이 되는 Invoice의 경우 별도 분기를 나눠 특화 모델을 구축할 예정.
→ Invoice (Date/Duration Specialized) 모델로 분기하여 진행 예정
Document AI
다이어그램 자료
User Flow
문서 업로드부터 후처리까지의 사용자 흐름
System Sequence (추가학습 포함)
시스템 간 상호작용 및 추가학습 순환 흐름
핵심 포인트: 문서 업로드 → 전처리 → OCR → AI 추론 자동 실행 → AI가 품질 점수/등급을 먼저 매김 → 사람은 필요한 것만 검수 → 확정 데이터는 저장 + 학습 데이터로 재사용 → 모델은 계속 개선 (추가학습)
데이터 라이프 사이클
데이터가 시스템을 순환하며 모델이 지속적으로 개선되는 구조
S3 데이터 구조
S3 Source
raw/ — 원본 PDF/PNG
processed/ — 전처리 완료 이미지
S3 Destination
data/ — Label Studio Export (완료 데이터)
results/ — 후처리 정규화 JSON
train-data/ — 학습용 Export (단일 JSON)
자동화 배치 주기
LayoutLM 배치 추론
주기: 30초
새 Task에 대해 자동 추론 + 품질등급 산출
Train Data Exporter
주기: 3시간
completed-only + incremental 방식으로 학습 데이터 수집
모델 추가학습
주기: 수동/스케줄
기존 checkpoint 기반 Fine-tuning 후 새 checkpoint 생성 및 배포