04 / 11
모델 학습
데이터 수집-정제-학습-검증-배포 파이프라인, 추가 학습, checkpoint 관리
학습용 / 테스트용 데이터 정리
학습용 데이터
| 선사 | 수량 | 비고 |
|---|---|---|
| 선사 A | 80개 | 금액 중심 |
| 선사 B | 55개 | 금액 중심 |
| 선사 C | 50개 | 금액 중심 |
| 선사 D | 50개 | 기간 중심 구조 |
| 선사 B (기간) | 20개 | 기간 위주 문서 |
| 합계 | 255개 |
테스트용 데이터
학습 전 품질 점수 (선사 D 기준)
Label Studio에서 quality_score / quality_grade 기반으로 측정한 학습 전 상태
| Annotations | quality_score | quality_grade | 누락 수 |
|---|---|---|---|
| 1 | 59.67 | D | 9 |
| 1 | 64.79 | D | 7 |
| 1 | 67.15 | D | 7 |
| 0 | 65.20 | D | 7 |
| 0 | 70.82 | C | 5 |
| 0 | 68.51 | D | 6 |
| 0 | 68.61 | D | 6 |
| 0 | 56.25 | D | 9 |
| 0 | 64.34 | D | 7 |
| 0 | 65.71 | D | 7 |
대부분 D등급 (56~68점대), 누락 필드 6~9개 → 추가 학습 필요
Data Characteristics
각 데이터 특징
선사 D 특징
SWB-NO. vs B/L No
같은 선사 D 문서여도 살짝 다름. BL_NUMBER 표기법이 다름 (SWB-NO. vs B/L-No)
선사 D는 다른 문서와 형식이 좀 다르다 → 학습 모델 분기 만들기 필요
Model Branching
학습 모델 분기 만들기
"기간" 기반 분기 — 선사 D
목적
Base 모델에서 필드를 확장하면서 도메인 이해도를 키우기.
정의
선사 D INVOICE를 보면 line_items 테이블 안에 기간 정보가 핵심으로 존재. 기존 설계에서는 주로 금액 중심이고, 날짜 및 기간은 보조적이었음.
선사 D line_item 예시
30.000 DAY80.00 USDFROM 2025-08-06 00:00TO 2025-09-04 24:00핵심: 선사 D에서는 "얼마를 청구했는가"보다 "기간"이 핵심 정보.30.000 → 기간 수치,DAY → 기간 단위
"필드 추가 + 추가 학습" 진행
의미적으로 독립된 필드 추가 → 라벨 스키마를 명확히 확장 → 해당 필드가 반복적으로 등장하는 문서들로 추가 학습 ⇒ 모델의 표현력을 확장하는 작업
"문서별 checkpoint 분리" 전략
base model → 데이터가 쌓이면 문서 타입(선사별)로 checkpoint 분리
Base LayoutLM
- •Invoice 전반 구조 이해
- •금액, 날짜, 고객/공급자 정보 공통 학습
선사 D 특화 checkpoint
- •
LINEITEM_DURATION_*필드 등장 - •Free time / Detention / Day 단위 요금 구조 학습
- •"기간 기반 요금" 패턴 강화
기존 checkpoint
금액 중심 Invoice
선사 A, C, B 같은 금액 중심 INVOICE
분리 checkpoint
기간/조건 중심 Invoice
선사 D처럼 기간/조건 중심 invoice
⇒ 한 개의 base 모델에서 여러 전문 모델 구조 파생이 자연스럽게 만들어짐. 선사 B에서도 문서 타입이 나뉘어 기간 중심 문서가 존재함.
정리
초기에는 금액 중심의 line item 구조로 설계했으나, 실제 선사별 invoice를 분석하면서 일부 문서에서는 '금액'보다 '기간 단위 조건'이 핵심이라는 점을 확인.
이에 따라 기존 모델을 폐기하지 않고, line item 의미를 확장하는 방식으로 필드를 추가하고 해당 문서 유형에 대해 추가 학습을 진행.
이 방식은 모델의 일반성을 유지하면서도, 문서 유형별 전문성을 점진적으로 강화할 수 있는 구조.
Checkpoint Structure
checkpoint 폴더 구조
LayoutLM / HuggingFace checkpoint 구성
checkpoint-246/ ├── config.json ├── model.safetensors (또는 pytorch_model.bin) ├── optimizer.pt (선택) ├── scheduler.pt (선택) └── trainer_state.json (선택)
학습된 가중치(weight). "이 모델이 어떤 패턴을 학습했는지"가 수치로 들어 있음. 추론 시 가장 핵심.
모델 구조 정의. label 수, id2label, label2id, hidden size 등. 추론 코드에서 model.config.id2label을 쓸 수 있는 이유.
학습 재개(resume training) 용. 추론에는 필요 없음.
👉 즉 checkpoint는 "뇌(가중치)"이지, "행동 방법(코드)"이 아님
GPU Server Training
GPU 서버에서의 학습 과정
학습과 추론의 분리
학습 (GPU 서버)
모델을 똑똑하게 만드는 과정
Fine-tuning → 새 checkpoint 생성
추론 (운영 파이프라인)
이미 학습된 모델로 예측
checkpoint 로드 → 필드 추출
GPU 서버에서 실제 하는 일
Label Studio에서 완료된 라벨 데이터(JSON) 수집
AI가 이해할 수 있는 학습 포맷으로 변환 (전처리)
기존 AI 모델을 기반으로 추가 학습 (Fine-tuning)
새로운 checkpoint 생성
학습 데이터 수집
Label Studio에서 사람이 라벨링 완료한 task를 JSON으로 추출. 주기마다 자동으로 전달됨.
JSON 구조
polygon→ 좌표 (bbox)textarea→ 텍스트labels→ 정답 라벨LayoutLM 입력 구성
다음의 3가지를 동시에 입력받도록 설계된 모델:
텍스트
token / input_id
위치 (레이아웃)
bbox [x0,y0,x1,y1]
이미지 특징
visual embedding
// 학습/추론 데이터 1개의 형태
{
"token": "INVOICE",
"input_id": 1234,
"bbox": [120, 45, 260, 80],
"label": "INVOICE_NUMBER" // 학습이면 정답, 추론이면 예측
}문서 1개 기준
words: ["<word_1>", "<word_2>", "<word_3>", ...] bboxes: [[x0,y0,x1,y1], ...] // 픽셀 좌표 labels: ["<LABEL_1>", ...] // 정답 or 예측
핵심 전처리: extract_words_from_tesseract_prediction()
id 기준 그룹핑
polygon + textarea를 같은 id로 묶어서 문서 1개 단위로 복원
word + bbox 추출
각 그룹에서 텍스트(word)와 좌표(bbox)를 뽑아냄
읽기 순서 정렬
줄 읽는 순서처럼 (cy, cx)로 정렬
Tokenization (LayoutLM 특이점)
전처리에서 나온 "단어 단위 데이터"에 tokenizer를 적용해서 token 단위 데이터로 변환.
// tokenizer 적용 후 input_ids[i] // 토큰 ID bbox[i] // 각 토큰의 좌표 position_ids[i] // 위치 정보
출처: LayoutLM 논문 + HuggingFace 공식 예제. sub-token 처리 방식은 LayoutLM 분석 페이지에서 상세 설명.
학습 방식: Fine-tuning
LayoutLM 사전학습 모델을 기반으로 한 Fine-tuning. 기존 지식을 유지하면서 우리 문서 도메인만 추가 학습.
| Base 모델 | LayoutLM 사전학습 모델 |
| 초기 학습 데이터 | 약 120개 샘플 |
| 학습 방식 | Fine-tuning (기존 지식 유지 + 도메인 추가 학습) |
| 결과물 | 새로운 checkpoint (가중치 + config) |
GPU 서버 학습 흐름
Continual Fine-tuning Verification
추가 학습 과정 검증
코드 설정 변경 사항
추가 학습 시 변경해야 하는 핵심 설정 3가지:
| 설정 | 설명 | 예시 |
|---|---|---|
CKPT_PATH | 이어서 학습할 기존 checkpoint 경로 | ./checkpoints-LayoutLM/checkpoint-246 |
EXPORT_PATHS | 새로 추가된 학습 데이터 경로 | 새 export 파일 추가 |
EPOCHS_TOTAL | 총 학습 epoch 수 | 최신 checkpoint 이어학습 시 고정 가능 |
실제 학습 코드: 데이터별 커스텀 추가 학습
학습 코드에서 추가 학습 데이터별로 커스텀하여 추가 학습을 진행할 수 있는 구조. EXPORT_PATHS, CKPT_PATH, EPOCHS_TOTAL 등을 변경하여 다양한 데이터셋에 대해 유연하게 이어학습이 가능합니다.
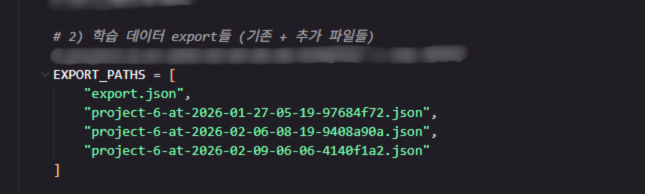
학습 코드에서 데이터별 커스텀 추가 학습 진행 구조
epoch / batch / step 개념
epoch전체 학습 데이터를 1번 다 보는 것 = step 여러 개 처리batch한 번에 묶어서 처리하는 데이터 수 (batch_size). 메모리 한계로 전체를 한 번에 못 넣음stepbatch 1개를 처리하고 가중치를 실제로 1번 업데이트하는 단위 (= optimizer 1회 업데이트)step ≠ 문서 개수, step ≠ epoch. step은 모델이 한 번 똑똑해진 순간 (= 가중치를 한 번 실제로 바꾼 순간). epoch가 "한 번에 학습하는 페이지 묶음"이라면, step은 "한 번 학습하고 실제로 기억 고친 횟수".
계산 예시
데이터 87개 ↓ (batch size = 2) [2개] [2개] [2개] ... [마지막 1개] ↓ step 1 step 2 step 3 ... step 44 ↓ 이게 전부 끝나면 = epoch 1 1 epoch = 87 ÷ 2 ≈ 44 steps 10 epochs = 44 × 10 = 440 steps
epoch를 늘리는 이유
• 모델이 데이터를 "더 깊게 익힌다" — 같은 데이터를 여러 번 반복 학습
• gradient가 점점 안정적인 방향으로 수렴
• 희귀한 패턴도 반복 노출 → 학습 가능성 ↑
문서 수가 적고(100여 개), 라벨 수가 많고(30+), LINE_ITEM같이 구조 복잡한 필드가 있으면 1~2 epoch은 부족
이어학습(Resume Training) 검증
기존 checkpoint-246에서 이어서 학습이 정상적으로 진행되었는지 확인. 모델 가중치 + optimizer + scheduler 상태를 checkpoint-246에서 그대로 이어받아 학습.
global_step (before)
246
기존 checkpoint
global_step (after)
440
학습 로그: Epoch 10/10
✅ step 246 → 440까지 실제로 추가 학습이 일어남
이게 안 됐으면: step이 0부터 시작하거나, before/after가 같은 값으로 나왔을 것. 250 이전(step 0~246)에 해당하는 학습은 이미 checkpoint-246을 만들 때 완료된 상태라서 이번 run에서는 다시 학습하지 않음. "이미 다 학습된 상태를 그대로 이어받는 것".
checkpoint-440 학습 과정 검증 화면
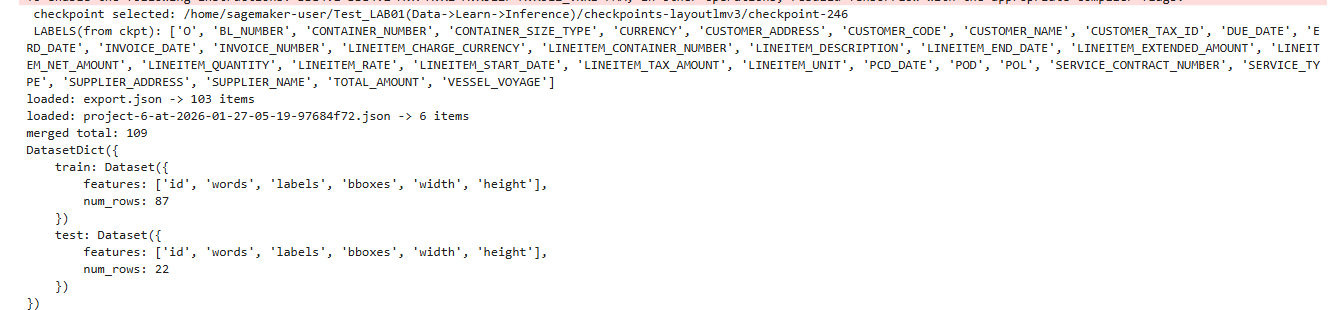
데이터 로드 및 학습 시작

Training Loss 추이
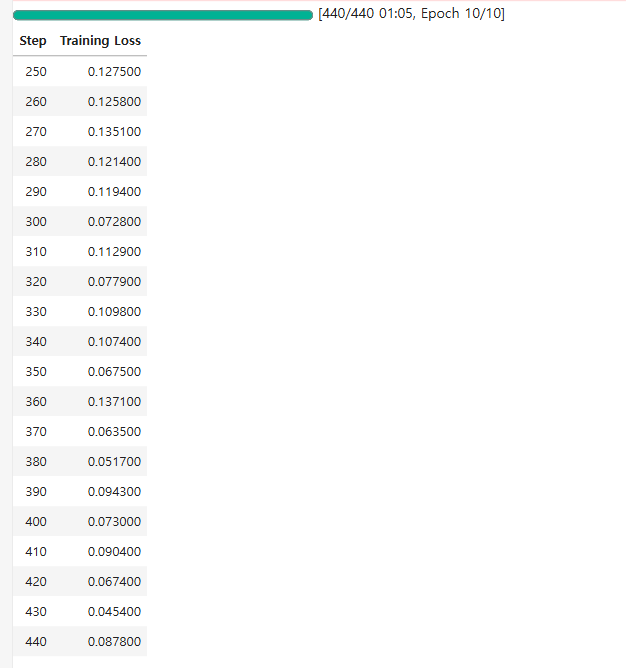
학습 로그 상세

평가 결과 확인
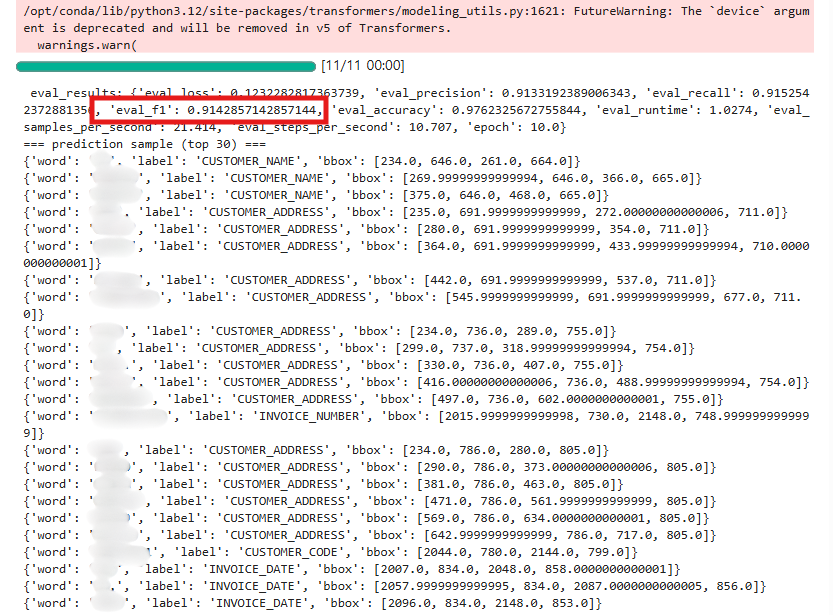
추론 샘플 확인
Training Loss 수렴 확인
step 250~440 구간의 loss 값 추이. 학습이 안정적으로 수렴하고 있는지 확인.
| Step | Training Loss |
|---|---|
| 250 | 0.1275 |
| 260 | 0.1258 |
| 270 | 0.1351 |
| 280 | 0.1214 |
| 290 | 0.1194 |
| 300 | 0.0728 |
| 310 | 0.1129 |
| 320 | 0.0779 |
| 330 | 0.1098 |
| 340 | 0.1074 |
| 350 | 0.0675 |
| 360 | 0.1371 |
| 370 | 0.0635 |
| 380 | 0.0517 |
| 390 | 0.0943 |
| 400 | 0.0730 |
| 410 | 0.0904 |
| 420 | 0.0674 |
| 430 | 0.0454 |
| 440 | 0.0878 |
✅ Loss가 0.1275 → 0.0454 수준으로 전반적 감소 추세 → 학습이 안정적으로 수렴 중
추가 데이터 반영 확인
기존 데이터
103개
추가 데이터
+6개
병합 후 전체
109개
| 구분 | 이전 | 이후 |
|---|---|---|
| Train (학습용) | 82개 | 87개 |
| Test (검증용) | 21개 | 22개 |
| epoch당 step 수 | 41 steps | 44 steps |
✅ 데이터가 늘어난 상태를 기준으로 epoch 계산이 다시 이루어졌고, 그 상태로 10 epoch 목표까지 학습됨.
F1 성능 개선
추가 학습 전
0.9107
checkpoint-246
추가 학습 후
0.9143
checkpoint-440
| 지표 | 값 |
|---|---|
| eval_loss | 0.1232 |
| eval_precision | 0.9133 |
| eval_recall | 0.9153 |
| eval_f1 | 0.9143 |
| eval_accuracy | 0.9763 |
✅ F1 Score: 0.9107 → 0.9143 (+0.0036 향상). 추가 데이터가 노이즈 없이 긍정적인 방향으로 작용.
F1 점수 해석 기준
F1 Score = Precision과 Recall의 조화 평균. "잘 맞춘 정도(정확도) + 놓치지 않은 정도(커버리지)"를 동시에 확인하는 지표.
Precision (정밀도)
모델이 맞다고 한 것 중에, 진짜 맞은 비율 → 높을수록 헛발질이 적다
Recall (재현율)
실제로 정답인 것 중에 모델이 얼마나 잡아냈는지 → 높을수록 놓치는 게 적다
Precision만 높다면 소심한 모델이고, Recall만 높다면 아무 데나 다 찍어서 오탐 많음. ⇒ 둘 다 높아야 좋은 모델.
| F1 범위 | 수준 | 설명 |
|---|---|---|
| 0.70 ~ 0.80 | 실험 단계 | 프로토타입 수준, 개선 필요 |
| 0.80 ~ 0.88 | 실무 가능 | 실무 투입 가능, 지속 개선 권장 |
| 0.90+ | 안정적 프로덕션 | 꽤 안정적인 프로덕션 수준 |
| 0.95+ | 고품질 | 데이터/라벨 매우 깔끔 + 도메인 고정 |
현재 F1 0.9143은 "안정적" 구간에 해당. 데이터 추가 시 0.95+ 도달 가능.
주의사항: 최신 checkpoint에서 시작
"checkpoint-246에서 시작했는데, 이게 잘된 건가?"
이건 "그 시점에 checkpoint-246이 최신이었는지"에 따라 갈림. 실무에서 제일 많이 하는 실수 포인트.
checkpoint-246이 최신이었다면
이전 학습 결과 위에 새 데이터(6개)를 포함해서 이어서 학습한 것 → 정석적인 continual fine-tuning 흐름
checkpoint-246보다 최신이 이미 있었는데 거기서 안 시작했다면
"누적 학습"이 아니라 "과거 상태에서 재학습"이 되는 것. 이후 학습된 내용이 모두 사라짐.
추가 학습 검증 요약
Training Time & Resource Usage
추가 학습 시 걸리는 시간 / 자원 소모
35개 추가 학습 실행 결과
추가 데이터
35건
End-to-End 소요 시간
3분 ~ 3분 30초
추가 학습 스텝
300 step
440 → 740
학습 중 인스턴스 자원 소모
CPU
32.60%
MEM
44.20%
Storage
86.04%
데이터 현황
| 항목 | 값 |
|---|---|
| merged total | 184개 |
| Train | 147개 |
| Test | 37개 |
총 소요시간 분해
"3~3분30초" 안에는 학습만 있는 게 아니라, 스크립트가 수행하는 전체 파이프라인 작업 시간이 포함됨.
A. 데이터 준비 / 정합성 체크 (CPU 위주)
• 여러 export JSON 로드 + merge → merged total: 184
• LS JSON → Dataset 변환 (ls_to_dataset): polygon + textarea + labels를 region_id로 묶어서 words/labels/bbox/width/height 형태로 변환
• 스키마 고정: checkpoint의 config.json에서 label2id/id2label 읽어와서 라벨 체계 고정. 새 데이터 라벨이 기존 스키마에 포함되는지 검증
• 토크나이즈 + bbox 정규화(0~1000) + 라벨 align: 첫 sub-token만 라벨 부여, labels=-100 처리로 loss 계산에서 제외
B. 모델/체크포인트 로드 및 resume 준비 (GPU/메모리)
• LayoutLMForTokenClassification.from_pretrained(CKPT_PATH)
• classifier head의 out_features가 num_labels와 일치하는지 검증
• trainer_state.json에서 global_step 읽기
C. 실제 추가 학습 (GPU 위주, 핵심)
• resume_from_checkpoint로 440 step에서 시작 → 740 step까지 진행 (추가 300 step)
• 학습 루프 시간: 약 1분 29초 (89초)
D. 검증/평가 + 샘플 추론
• evaluate()로 test split 평가 — eval_runtime: ~1.7초
• 샘플 1개 추론 (predict_v3): 토크나이즈 → forward → token-level 예측 → word-level 대표 토큰 추출
시간 요약
| 구간 | 소요 시간 |
|---|---|
| 학습 루프 (Trainer) | ~89초 |
| 평가 (seqeval) | ~1.7초 |
| 데이터 전처리 + 모델 로딩 + IO | ~1.5~2분 |
| 전체 End-to-End | 3~3.5분 |
End-to-End로 "추가 데이터 반영 → 재학습 → 성능평가 → 추론 확인"까지 한 번에 도는 파이프라인 실행 시간이 3분대.
Training Loss (step 450~740)
checkpoint-440에서 이어학습. [740/740 01:29, Epoch 10/10]
| Step | Training Loss |
|---|---|
| 450 | 0.2041 |
| 460 | 0.1539 |
| 470 | 0.0733 |
| 480 | 0.1328 |
| 490 | 0.1160 |
| 500 | 0.0575 |
| 510 | 0.0919 |
| 520 | 0.0486 |
| 530 | 0.0667 |
| 540 | 0.0817 |
| 550 | 0.0518 |
| 560 | 0.0945 |
| 570 | 0.0511 |
| 580 | 0.0731 |
| 590 | 0.0500 |
| 600 | 0.0450 |
| 690 | 0.0248 |
| 700 | 0.0444 |
| 710 | 0.0337 |
| 720 | 0.0338 |
| 730 | 0.0759 |
| 740 | 0.0376 |
✅ Loss가 0.2041 → 0.0376 수준으로 전반적 감소 추세. global_step(after): 740 확인.
평가 결과 (checkpoint-740)
| 지표 | 값 |
|---|---|
| eval_loss | 0.0616 |
| eval_precision | 0.9526 |
| eval_recall | 0.9604 |
| eval_f1 | 0.9565 |
| eval_accuracy | 0.9762 |
✅ F1: 0.9143 → 0.9565 (+0.0422 향상). 0.95+ 고품질 구간 진입.

checkpoint-740 평가 결과 — F1 0.9565 달성
학습 시간 / 자원 요약