10 / 11
BIO 라벨 & 학습 개선
B-I-O 태깅 도입, Classifier Head 확장, 행 경계 학습, 학습 결과 검증
학습 로직 개선: 라벨 추가 시 Classifier Head 확장
LayoutLMv3ForTokenClassification 모델 구조는 크게 두 부분입니다:
LayoutLMv3 본체 (Encoder)
텍스트 + 위치 정보를 이해하는 부분
Classifier Head (Linear Layer)
"이 토큰이 어떤 라벨인지" 분류하는 부분
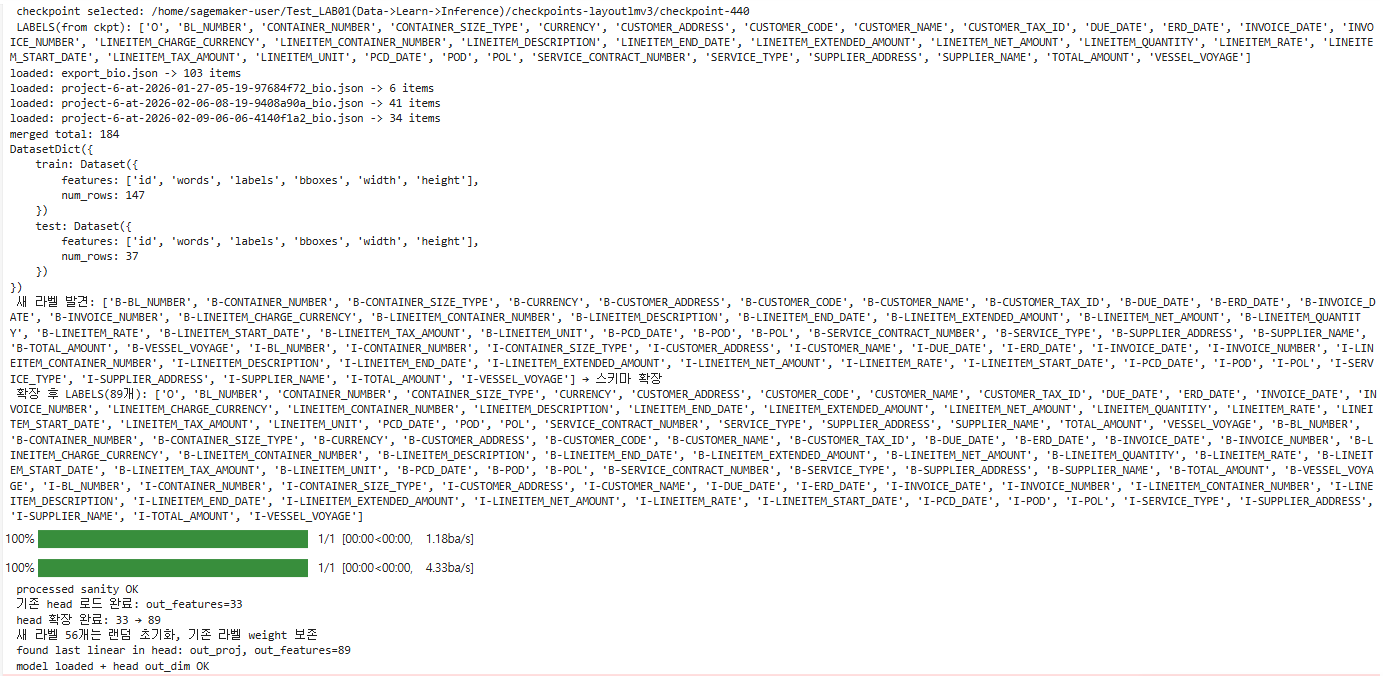
현재 Checkpoint의 Classifier Head
Linear(in_features=768, out_features=33)out_features=33인 이유: 기존 라벨이 33개(O 포함)이기 때문. weight 행렬 shape = (33, 768)
문제: 새 라벨 추가 시 shape 불일치
새 라벨 5개 추가 → 총 38개 → (38, 768) weight 필요 → 기존 checkpoint에는 (33, 768)만 저장 → 로드 불가
Classifier Head 확장 방법
기존 checkpoint에서 (33, 768) weight 로드
새로운 (38, 768) weight 생성
기존 33개 라벨에 해당하는 행은 학습된 값을 그대로 복사
새로 추가된 5개 라벨에 해당하는 행만 랜덤 초기화
✅ 기존에 학습한 지식은 보존하면서 새 라벨만 추가로 학습 가능. 처음부터 다시 학습하는 것보다 훨씬 효율적.
BIO Tagging
B-I-O 라벨 태그 도입
라벨링 규칙
O관심 없는 토큰 (기존과 동일)B-라벨명해당 필드의 첫 번째 단어I-라벨명해당 필드의 연속 단어 (같은 셀 안에서)모든 라벨에 적용합니다. 헤더 필드든 표 필드든 동일.
비표 영역 (단일 값 필드) 예시
단어: 7535962046 라벨: B-INVOICE_NUMBER ← 단어 1개면 B만 단어: LX 라벨: B-CUSTOMER_NAME ← 여러 단어면 B로 시작 단어: PANTOS 라벨: I-CUSTOMER_NAME ← 이어지는 단어는 I 단어: MEXICO 라벨: I-CUSTOMER_NAME
표 영역 (반복되는 행) 예시
[1행] 단어: CAAU8385778 라벨: B-CONTAINER_NUMBER 단어: 40/9'6/DRY 라벨: B-CONTAINER_SIZE_TYPE 단어: SD-CY 라벨: B-SERVICE_TYPE 단어: Sep 라벨: B-PCD_DATE 단어: 11, 라벨: I-PCD_DATE 단어: 2025 라벨: I-PCD_DATE [2행] 단어: CAAU8459865 라벨: B-CONTAINER_NUMBER ← B가 다시 나옴 = 새 행 단어: 40/9'6/DRY 라벨: B-CONTAINER_SIZE_TYPE 단어: SD-CY 라벨: B-SERVICE_TYPE 단어: Sep 라벨: B-PCD_DATE 단어: 11, 라벨: I-PCD_DATE 단어: 2025 라벨: I-PCD_DATE
라벨 수 변화
현재
33개
O + 32개 라벨
BIO 적용 후
65개
O + 32개 × 2 (B-, I-)
Key Benefit
핵심: 행 경계를 모델이 직접 알려준다
현재 방식의 문제
모델 출력: 54.00 → LINEITEM_RATE 732.00 → LINEITEM_RATE 50.00 → LINEITEM_RATE
LINEITEM_RATE가 3개 나왔지만, 어떤 RATE가 어떤 DESCRIPTION과 같은 행인지 알 수 없음. 현재는 "y좌표가 비슷하면 같은 행"이라는 후처리 규칙에 의존.
B-I 적용 후
모델 출력: Emission → B-LINEITEM_DESCRIPTION ← 1행 시작 Surcharge → I-LINEITEM_DESCRIPTION 3 → B-LINEITEM_QUANTITY 54.00 → B-LINEITEM_RATE USD → B-LINEITEM_CHARGE_CURRENCY 162.00 → B-LINEITEM_NET_AMOUNT Basic → B-LINEITEM_DESCRIPTION ← 2행 시작 (B가 다시 나옴) Ocean → I-LINEITEM_DESCRIPTION Freight → I-LINEITEM_DESCRIPTION 3 → B-LINEITEM_QUANTITY 732.00 → B-LINEITEM_RATE USD → B-LINEITEM_CHARGE_CURRENCY 2,196.00 → B-LINEITEM_NET_AMOUNT
파싱 결과:
행 1: {DESC: "Emission Surcharge", QTY: "3", RATE: "54.00", CURRENCY: "USD", AMOUNT: "162.00"}
행 2: {DESC: "Basic Ocean Freight", QTY: "3", RATE: "732.00", CURRENCY: "USD", AMOUNT: "2,196.00"}
y좌표 계산 없이, 모델 출력 순서만으로 행이 구분됩니다. B가 나오면 새 행 열기, I가 나오면 현재 행에 이어붙이기만 하면 됩니다.
Model Learning
LayoutLM 내부 학습 방법
입력 단계
모델에 들어가는 입력은 토큰마다 3가지 정보입니다:
토큰: "CAAU8385778" ├─ 텍스트 임베딩: "CAAU8385778"이라는 문자열의 의미 벡터 ├─ 위치 임베딩: bbox [350, 1200, 580, 1230] → 0~1000 정규화 좌표 └─ 1D 위치 임베딩: 시퀀스에서 몇 번째 토큰인지
이 세 가지를 더해서 하나의 벡터(768차원)로 만듭니다. 이게 각 토큰의 초기 표현입니다.
Transformer Encoder
12개 레이어의 self-attention을 통과합니다:
"CAAU8385778"이 주변 토큰들을 봄: - 왼쪽에 "Container No"라는 헤더가 있네 → 컨테이너 번호일 가능성 높음 - 위치가 y=1200 근처네 → 표의 특정 행 - 바로 아래 y=1250에 "CAAU8459865"가 있네 → 다른 행의 같은 컬럼
self-attention이 텍스트 내용과 위치를 동시에 보면서, 각 토큰이 문서 전체 맥락에서 어떤 역할인지를 768차원 벡터에 압축합니다.
Classifier Head & 학습 (역전파)
[768차원 벡터] → Linear(768, 89) → [89개 라벨 확률] 예: "CAAU8385778" O: 0.01 B-CONTAINER_NUMBER: 0.92 ← 가장 높음 I-CONTAINER_NUMBER: 0.03 B-INVOICE_NUMBER: 0.01 ...
정답 라벨과 예측을 비교해서 CrossEntropyLoss를 계산하고, 역전파로 weight를 업데이트합니다.
B-I를 어떻게 구분하는가
핵심은 위치 임베딩입니다:
1행: "CAAU8385778" (y=1200) → B-CONTAINER_NUMBER 2행: "CAAU8459865" (y=1250) → B-CONTAINER_NUMBER (y가 바뀜 → 새 행 → B) 같은 셀: "Sep" (y=1200, x=600) → B-PCD_DATE 같은 셀: "11," (y=1200, x=630) → I-PCD_DATE (y 같고 x만 약간 이동 → 연속 → I)
학습 데이터에서 이 패턴을 반복적으로 보면, 모델이 "y좌표가 비슷하고 같은 라벨이면 I-, y좌표가 크게 바뀌면 B-"를 자연스럽게 학습합니다. 우리가 규칙을 정의한 게 아니라 모델이 데이터에서 패턴을 찾아낸 것입니다.
Code Changes (0331)
학습 코드 변경 사항
주요 변경 3가지
8-4) 라벨 검증 → 자동 확장으로 변경
B-I 라벨(B-CONTAINER_NUMBER, I-CONTAINER_NUMBER 등)이 기존 checkpoint에 없으니까, 자동으로 스키마를 확장합니다.
8-6) 모델 로드 → Head 확장 로직 추가
8-9) 학습 실행 → Head 확장 시 Resume 비활성화
head 크기가 바뀌면 optimizer state shape이 안 맞아서 resume이 불가능. 대신 encoder weight는 이미 checkpoint에서 로드된 상태라 보존됩니다.
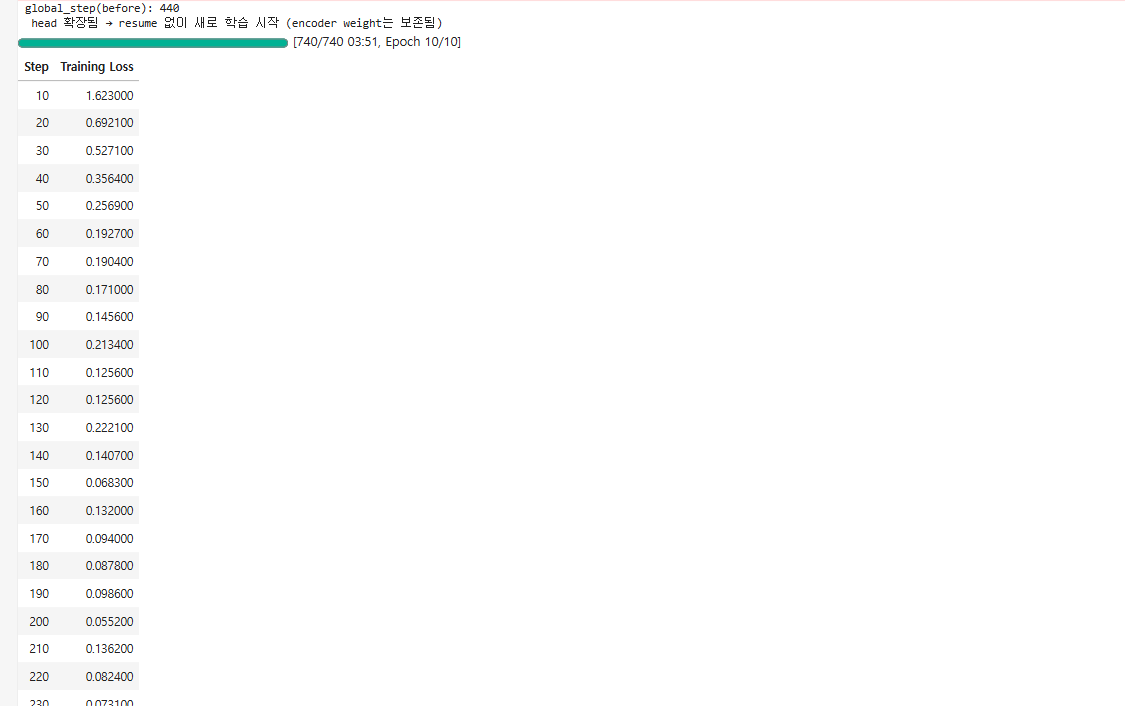
Training Result
BIO 학습 결과
학습 결과 요약
라벨 수
33 → 89
B-I 태깅 적용
Head 확장
33 → 89
기존 weight 보존 + 56개 새 라벨 랜덤 초기화
| 지표 | 값 |
|---|---|
| 학습 | 10 epoch, 740 step |
| Loss | 1.623 → 0.026 |
| eval F1 | 0.954 |
| eval Precision | 0.951 |
| eval Recall | 0.957 |
| eval Accuracy | 0.987 |
✅ 이전 학습(B-I 없이) F1 0.956 → BIO 적용 후 F1 0.954로 거의 동일. 라벨 수가 33에서 89로 거의 3배 늘었는데도 성능이 유지된 건 좋은 신호.
Prediction 샘플 검증
B-I가 잘 동작하고 있는 예시:
CUSTOMER_NAME
B-CUSTOMER_NAME → I-CUSTOMER_NAME → I-CUSTOMER_NAME
→ "PANTOS POLAND SP ZOO"가 하나의 엔티티
SUPPLIER_NAME
B-SUPPLIER_NAME → I-SUPPLIER_NAME → ...
→ "CMA CGM POLSKA SP Z OO"가 하나의 엔티티
VESSEL_VOYAGE
B-VESSEL_VOYAGE → I-VESSEL_VOYAGE
→ "CMA CGM CENTAURUS"가 하나의 엔티티
학습 결과 확인 화면
BIO 학습 결과 1
BIO 학습 결과 2

BIO 학습 결과 3
라벨링 가이드
작업 순서
Label Studio에 B-/I- 라벨 등록
40건 데이터를 B-I-O 방식으로 라벨링
가장 시간이 걸리는 단계
export.json 추출
노트북에서 EXPORT_PATHS에 추가 후 학습 실행
head 자동 확장
학습 완료 후 추론 코드에 B-I 파싱 로직 추가
추론 코드 변경 (학습 후)
추론 결과에서 B-/I-를 파싱하는 로직이 필요합니다. layoutlm_batch_predict_paddle_latin.py에 추가:
# 모델 출력 예시:
["O", "B-CONTAINER_NUMBER", "B-CONTAINER_SIZE_TYPE",
"B-PCD_DATE", "I-PCD_DATE", "I-PCD_DATE",
"B-CONTAINER_NUMBER", ...]
# 파싱 결과:
# 엔티티 1: {label: "CONTAINER_NUMBER", text: "CAAU8385778"}
# 엔티티 2: {label: "CONTAINER_SIZE_TYPE", text: "40/9'6/DRY"}
# 엔티티 3: {label: "PCD_DATE", text: "Sep 11, 2025"} ← B+I+I 합침
# 엔티티 4: {label: "CONTAINER_NUMBER", text: "CAAU8459865"} ← 새 행같은 라벨의 B가 다시 나오면 새 행으로 그룹핑 가능.
BIO 도입 요약