06 / 11
LayoutLM 분석
sub-token 처리, Invoice 공통 필드 추출, 성능 지표 분석
배경: 단일 모델로 공통 필드 추출이 가능한가?
차후에는 프로젝트별로 학습 모델을 따로 가져가는 방향도 있지만, 일단은 한 개의 BASE model을 여러 서비스/프로젝트들이 같이 쓰는 구조.
결론: Invoice 포맷이 회사마다 달라도 LayoutLM 같은 모델 한 개로 공통 필드(INVOICE_NUMBER 등)를 추출하는 건 기술적으로 가능. 단, "위치 규칙"이 아니라 "의미 + 레이아웃 패턴"으로 학습했을 때만 가능.
문제 정의
선사마다 INVOICE NUMBER의 위치가 전부 다름:
"위치가 다 다른데, 어떻게 단일 모델로 처리?"
핵심: 모델은 "절대 좌표"를 외우지 않음
✗ 이렇게 학습하지 않음
"x=120, y=80 근처에 있으면 INVOICE_NUMBER다"
✓ 실제 학습 방식
"이 토큰이 어떤 텍스트인지, 문서에서 어디쯤에 있는지(상단/하단/좌/우), 주변에 어떤 텍스트들이 있는지, 어떤 시각적 구조에 속해 있는지를 종합적으로 보고 판단"
즉, 위치는 단서 중 하나일 뿐 결정적인 요소가 아님.
무엇을 보고 INVOICE_NUMBER라고 판단하는가?
텍스트 의미 (가장 강함)
근처에 다음과 같은 단어들이 있으면 강력한 힌트:
InvoiceInvoice NoInv. NumberInvoice #No.레이아웃 상대 위치
- •문서 상단, header 영역
- •다른 핵심 메타데이터들과 가까움 (DATE, CUSTOMER, TOTAL 등)
- •→ "문서 구조상 중요한 정보 구역"에 위치
주변 문맥
Invoice No: 12345678 Date: 2024-01-15
Invoice No → 라벨 힌트, 뒤의 숫자 → 값Date가 있음 → header 메타데이터 확신반복 패턴 학습 (일반화)
학습 데이터가 쌓이면 모델은 이렇게 일반화함:
"회사 A에서는 왼쪽 상단, 회사 B에서는 오른쪽 상단이지만 둘 다 문서 상단 + 메타데이터 블록에 있음"
→ 이것이 일반화 능력
따라서 "한 개의 모델"로 가능
INVOICE_NUMBER = "이 문서를 대표하는 고유 식별자"
그 역할은:
→ 위치는 다르지만 역할은 같다
비효율적
회사별 모델 N개
선사마다 별도 모델 유지 → 관리 비용 증가
효율적
한 개의 모델 + 다양한 학습 샘플
의미 + 레이아웃 패턴 기반 일반화
Architecture
LayoutLM 입력 구조 & 사전학습
LayoutLM 입력 구조
LayoutLM는 문서의 텍스트, 위치, 이미지 정보를 동시에 이해하도록 사전학습(pre-training)된 모델. 입력은 다음 임베딩들의 조합:
1D Position Embedding
→ 이 토큰이 문서에서 몇 번째 순서인가?
2D Position Embedding
→ 이 토큰이 문서의 어디(x, y)에 위치해 있는가?
Word / Patch Embedding
→ 이 토큰(텍스트/이미지)의 의미 자체는 무엇인가?
Image Patches
→ 문서 이미지를 패치 단위로 분할하여 시각적 특징 추출
input = token_embedding // 단어 의미
+ 1D_position_embedding // 순서 정보
+ 2D_position_embedding // 문서 내 좌표 (x, y)
+ visual_embedding // 이미지 패치 특징사전학습 (Pre-training) Heads
MLM Head
Masked Language Modeling — 텍스트 이해 학습
문장 중 일부 단어를 가리고, 그 단어를 맞추도록 학습. BERT 계열의 기본 학습 방식.
예시
Invoice No: [MASK] → 모델이 Invoice Number 패턴을 이해하도록 학습
WPA Head
Word-Patch Alignment — 텍스트 ↔ 이미지 정렬 학습
이 단어가 실제로 문서 이미지의 이 위치와 맞는지 학습. 단어와 시각적 영역을 연결하는 능력.
예시
"Total"이라는 단어 → 실제 이미지에서 오른쪽 하단에 있음 → 모델이 단어와 시각적 영역을 연결하도록 학습
MIM Head
Masked Image Modeling — 이미지 이해 학습
문서 이미지 일부를 가리고, 그 부분을 복원하도록 학습. 문서의 시각적 구조를 이해하는 능력.
예시
테이블 일부를 가림 → 모델이 그 구조를 이해하도록 학습
Summary
| Head | 학습 대상 | 효과 |
|---|---|---|
| MLM | 텍스트 | 문맥 이해 |
| WPA | 텍스트 ↔ 이미지 | 위치 정렬 |
| MIM | 이미지 | 레이아웃/구조 이해 |
→ 세 가지 Head가 결합되어 텍스트 + 위치 + 시각 정보를 동시에 학습
Tokenization
Sub-token 처리에 대한 이해
LayoutLM/BERT 계열의 토큰화 문제
모델은 "단어 단위로" 학습되지 않음. 하지만 정답(라벨)은 단어 단위로만 존재. 이 불일치가 sub-token 처리의 출발점.
첫 sub-token을 쓰는 이유: "정답 라벨이 애초에 그 위치에만 존재하도록 학습시킴"
학습 데이터는 단어 단위
학습 데이터 (단어 단위)
words = ["ACME", "LOGISTICS", "MEXICO"] labels = ["CUSTOMER_NAME", "CUSTOMER_NAME", "CUSTOMER_NAME"]
→ 정답 라벨은 단어 단위로만 존재
Tokenizer가 단어를 쪼갬
Tokenizer 결과
"LOGISTICS" → ["LOG", "##IST", "##ICS"] "MEXICO" → ["ME", "##X", "##ICO"]
모델 입력 (토큰 단위)
토큰: ["ACME", "LOG", "##IST", "##ICS", "ME", "##X", "##ICO"]
문제: 정답 라벨은 3개인데, 토큰은 7개 → 라벨 수가 맞지 않음
해결: 첫 sub-token만 정답 라벨 부여
LayoutLM/BERT 계열의 표준 규칙: 첫 sub-token만 정답 라벨을 주고, 나머지는 -100으로 학습에서 제외.
| sub-token | label | 역할 |
|---|---|---|
| ACME | CUSTOMER_NAME | 단어 대표 (1-token 단어) |
| LOG | CUSTOMER_NAME | "LOGISTICS"의 첫 sub-token |
| ##IST | -100 | 학습 제외 |
| ##ICS | -100 | 학습 제외 |
| ME | CUSTOMER_NAME | "MEXICO"의 첫 sub-token |
| ##X | -100 | 학습 제외 |
| ##ICO | -100 | 학습 제외 |
→ 모델은 '첫 sub-token 위치'에만 의미 있는 라벨을 예측하도록 학습됨
'ME' ≠ CUSTOMER_NAME
'ME'라는 문자열 자체가 CUSTOMER_NAME으로 분류되는 게 아님. 'MEXICO'라는 단어 전체의 문맥/위치/레이아웃을 대표하는 토큰이 우연히 첫 sub-token인 'ME'일 뿐.
✗ 잘못된 이해
"ME"라는 글자가 CUSTOMER_NAME이다
✓ 올바른 이해
이 위치에 있는 이 단어(=MEXICO)는 CUSTOMER_NAME이다. 'ME'는 그 단어의 대표 토큰일 뿐.
모델은 토큰을 '혼자' 보지 않는다
LayoutLM가 실제로 보는 입력:
token_embedding // 토큰의 의미 + 2D_position_embedding // 문서 내 2D 좌표 + 1D_sequence_embedding // 순서 정보 + visual_embedding // 이미지 특징
self-attention: 이 토큰의 의미를 판단할 때 문서 안의 다른 모든 토큰들을 동시에 참고
'ME'가 CUSTOMER_NAME으로 예측될 때 참고하는 정보
같은 단어의 나머지 sub-token들
##X, ##ICO → attention으로 강하게 연결됨
같은 줄/같은 블록의 단어들
ACME LOGISTICS MEXICO → 회사명 블록이라는 것을 인식
문서 레이아웃 정보
좌측 상단, 주소/수신자 영역, 테이블 바깥, 헤더 근처 → CUSTOMER_NAME이 자주 나오는 위치
이미지 특징 (LayoutLM)
글씨 크기, Bold 여부, 주변 박스 구조
한 마디로: 이 맥락에서 'ME'는 "이 위치에 있는 이 단어(=MEXICO)는 CUSTOMER_NAME이다"라는 뜻
Confidence 처리
LayoutLM는 모든 sub-token에 대해 logits(라벨별 점수) 출력
softmax → confidence(확률) 변환
모든 sub-token은 confidence를 갖지만, self-attention으로 인해 첫 sub-token confidence에 이미 반영됨
후처리에서 첫 sub-token만 대표로 사용
필드 confidence는 "단어 단위 confidence"를 집계한 것. 대부분 첫 번째 sub-token의 confidence가 가장 높게 나오며, 이는 우연이 아니라 LayoutLM의 학습 구조 + self-attention 때문.
Sub-token의 이점: 왜 이렇게 복잡하게 하는가?
전통적 접근 (규칙 기반)
"단어 단위로 잘라서 단어를 그대로 이해하자"
→ Invoice / 물류 문서에서는 바로 깨짐
BERT / LayoutLM 접근
sub-token 단위로 분석. 모르는 단어도 sub-token 조합으로 처리.
→ OOV(Out-of-Vocabulary) 문제 해결
다음과 같은 것들을 사전(vocabulary)에 전부 넣는 건 불가능:
MEXICOMSKU1234567INV-2025-0001930,000DAY⇒ "단어를 외우는 모델"을 포기하고, sub-token 조합으로 어떤 단어든 처리할 수 있는 구조를 채택
Summary
Tokenizer가 단어를 sub-token으로 쪼개면 라벨 수 불일치 발생
첫 sub-token만 정답 라벨 부여, 나머지는 -100 (학습 제외)
모델은 self-attention으로 문서 전체 맥락을 동시에 참고
첫 sub-token의 confidence가 단어 전체를 대표
sub-token 방식으로 OOV 문제 해결 → 물류 문서의 다양한 단어 처리 가능
Evaluation
학습 모델 성능 지표
성능 측정 체계 구축
목표
Document AI를 "모델 개발 중심 단계"에서 "측정 가능한 ML 시스템 단계"로 전환. 지금 시점에 필요한 건 모델 개선이 아니라 "측정 체계 구축".
0단계
기준 고정
완료1단계
OCR 성능 측정
완료2단계
KIE 성능 측정
진행 중3단계
문서 단위 KPI
예정4단계
bbox 품질
예정5단계
오답 분석
예정6단계
MLflow 도입
진행 중7~8단계
파이프라인 연결
예정0단계 — 평가 기준 고정
평가 기준을 먼저 고정하지 않으면 모든 지표가 무의미해짐. 평가 대상 필드, 텍스트 정규화 규칙, 필드별 비교 규칙, 데이터셋 분할 규칙을 확정.
핵심 필드 (7개)
보조 필드 (19개)
필드별 비교 규칙
| 필드 유형 | 비교 방식 | 예시 |
|---|---|---|
| ID/번호형 | 매우 엄격 (공백 제거만 허용) | INVOICE_NUMBER, BL_NUMBER |
| 날짜형 | 구분자 차이 허용, zero-padding 통일 | PCD_DATE, ERD_DATE |
| 금액형 | 쉼표 제거, 소수점 정책 정의 | TOTAL_AMOUNT |
| 일반 문자열 | 대소문자 무시, 연속 공백 무시 | CUSTOMER_NAME |
데이터셋 분할 규칙
train 70% / val 15% / test 15%. Document AI는 같은 양식이 train/test에 섞이면 성능이 과대평가되기 쉬움. 1차: 랜덤 split으로 baseline 구축 → 2차: 템플릿/고객사 기준 분할 (hard/generalization test).
1단계 — OCR 성능 측정
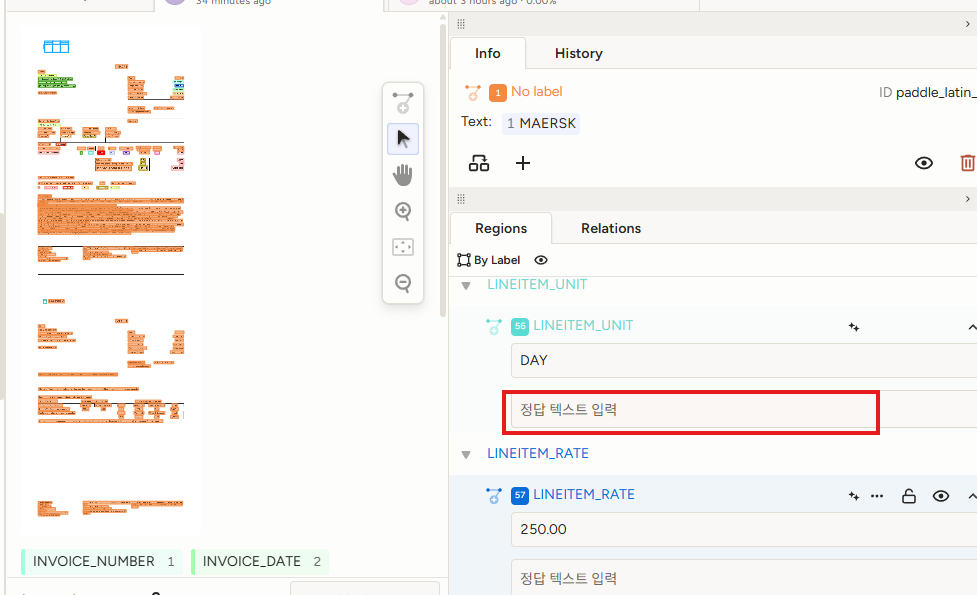
Tesseract vs PaddleOCR 정량 비교. Label Studio에서 사람이 검수한 corrected_text(정답)와 OCR 결과를 비교하여 CER/WER/Exact Match/Normalized Match를 계산.
OCR 성능 측정 흐름
OCR 전체 성능 (30개 문서, 370 샘플 기준)
1.55%
CER
1.55%
WER
98.9%
Exact Match
98.9%
Normalized Match
필드별 OCR 성능
| 필드 | Count | CER | Exact Match |
|---|---|---|---|
| INVOICE_NUMBER | 30 | 0.0% | 100% |
| INVOICE_DATE | 28 | 0.0% | 100% |
| DUE_DATE | 28 | 0.0% | 100% |
| CUSTOMER_CODE | 27 | 0.0% | 100% |
| CUSTOMER_ADDRESS | 86 | 0.0% | 100% |
| VESSEL_VOYAGE | 29 | 0.0% | 100% |
| POL | 28 | 0.0% | 100% |
| POD | 28 | 0.0% | 100% |
| SUPPLIER_NAME | 7 | 0.0% | 100% |
| BL_NUMBER | 23 | 0.0% | 100% |
| CUSTOMER_NAME | 30 | 15.9% | 93.3% |
| SUPPLIER_ADDRESS | 26 | 3.7% | 92.3% |
CUSTOMER_NAME: CER 15.9%, EM 93.3% — 고객명 OCR 깨짐 일부 발생. SUPPLIER_ADDRESS: CER 3.7%, EM 92.3% — 긴 주소 문자열에서 OCR 깨짐 발생.
MLflow — OCR 성능 추적
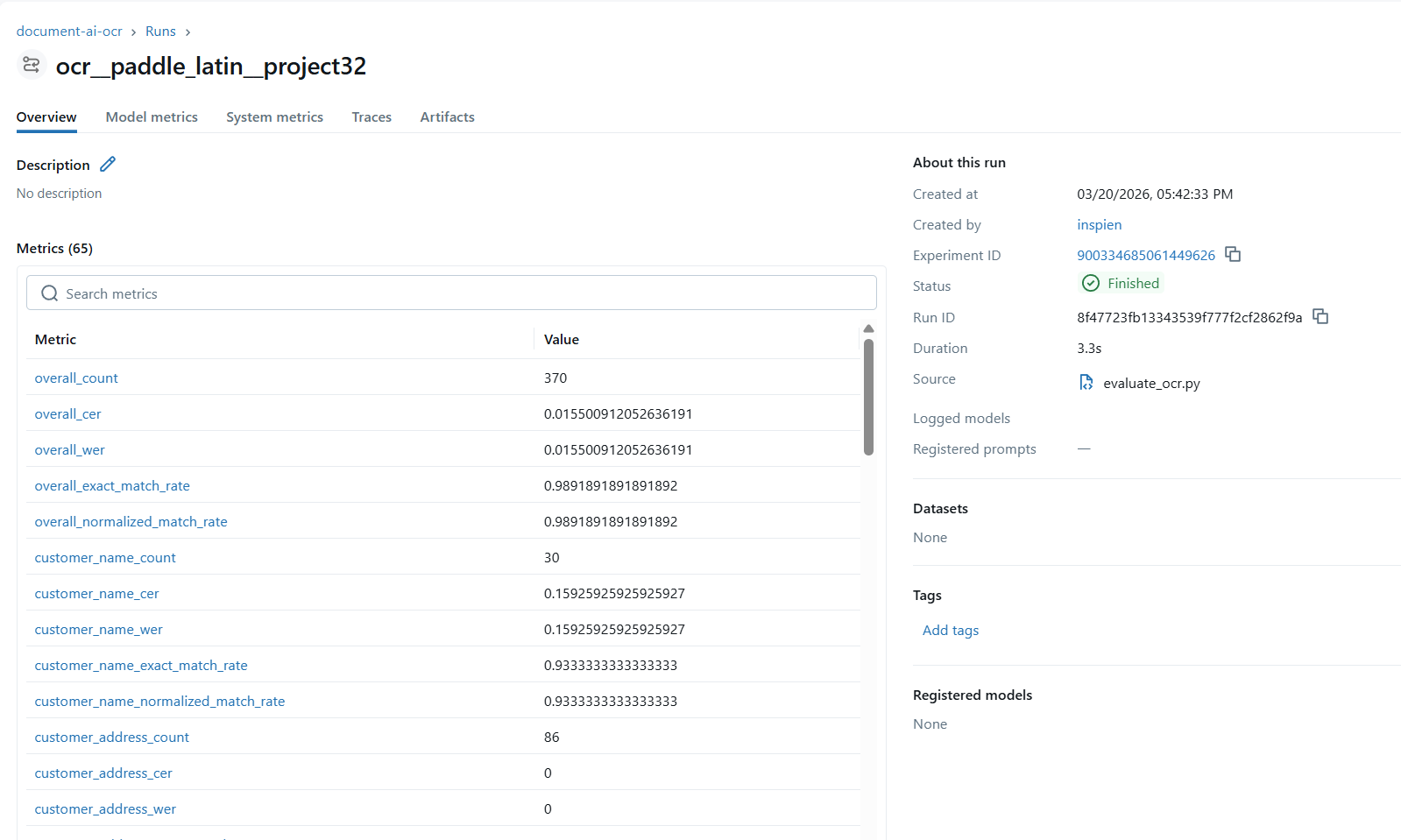
PaddleOCR 성능 추적 — CER/WER/EM 지표
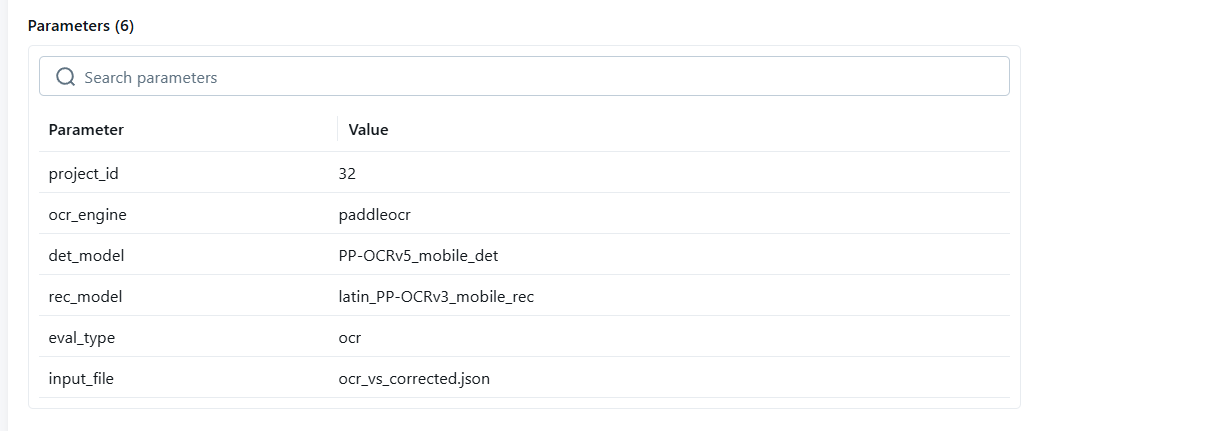
PaddleOCR 필드별 성능 상세
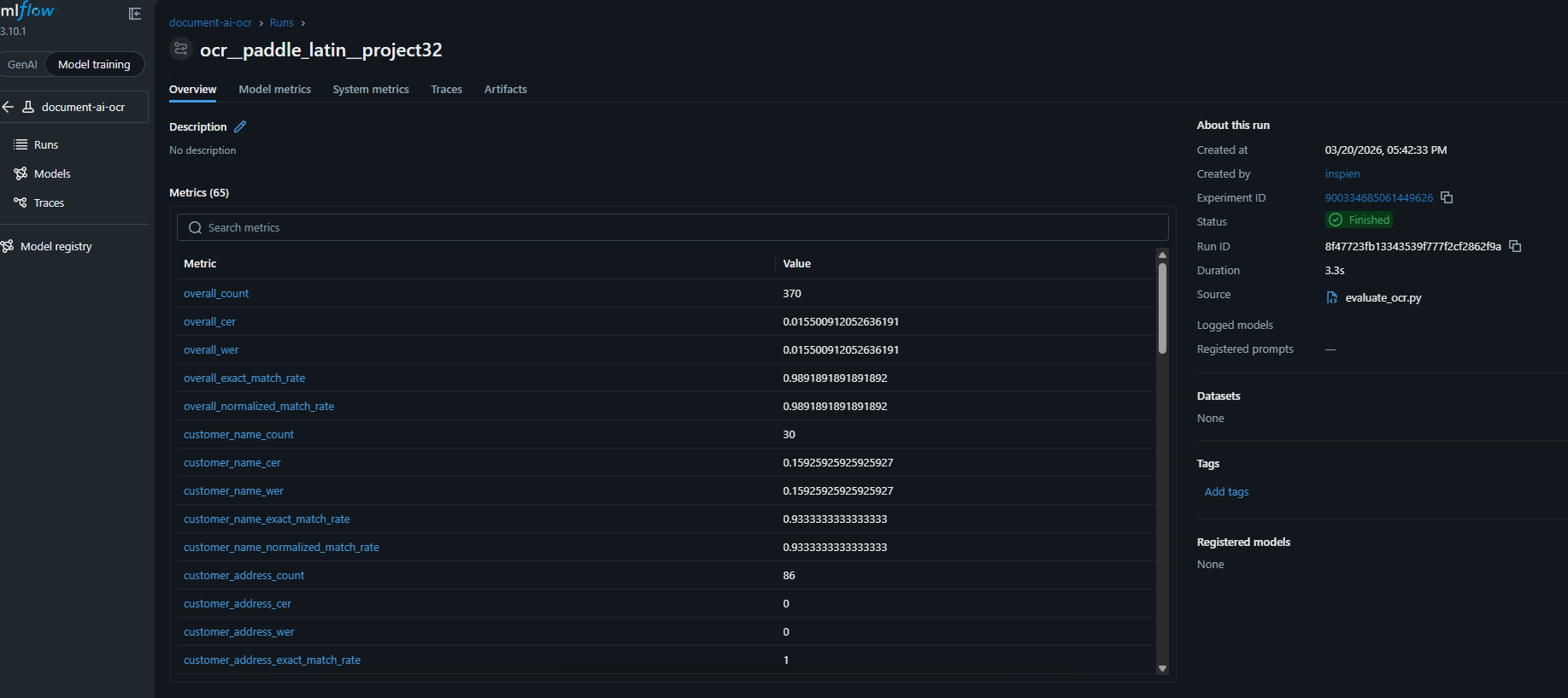
2단계 — LayoutLM (KIE) 성능 측정
checkpoint 성능을 숫자로 확인. GT(정답): Label Studio에서 사람이 검수한 label vs Pred(예측): predictions 안의 LayoutLM 예측 label을 비교하여 Precision/Recall/F1을 계산.
좋은 모델
Precision 높음 → 헛다리 적음
Recall 높음 → 놓치는 것 적음
나쁜 모델
Precision만 높음 → 데이터 누락
Recall만 높음 → 데이터 오염
Checkpoint별 F1 Score 비교
| checkpoint | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| checkpoint-440 | 0.9087 | 0.9200 | 0.9143 | 0.9812 |
| checkpoint-740 | 0.9526 | 0.9604 | 0.9565 | 0.9876 |
checkpoint-740 상세 평가 결과
| 지표 | 값 |
|---|---|
eval_loss손실값 | 0.0062 |
eval_precision정밀도 | 0.9526 |
eval_recall재현율 | 0.9604 |
eval_f1F1 Score | 0.9565 |
eval_accuracy정확도 | 0.9876 |
epoch학습 에폭 | 10.0 |
eval_samples_per_second: 21.398 / eval_steps_per_second: 10.988
예측 샘플 (Top 7)
| word | label |
|---|---|
| PLTN0504B2 | INVOICE_NUMBER |
| 0000892220KR01 | CUSTOMER_CODE |
| 08-SEP-2025 | INVOICE_DATE |
| ACME | CUSTOMER_NAME |
| POLAND | CUSTOMER_NAME |
| SP. | CUSTOMER_NAME |
| ZOO | CUSTOMER_NAME |
CUSTOMER_NAME이 여러 토큰에 걸쳐 정확히 추출됨 (ACME LOGISTICS POLAND SP. ZOO → 하나의 고객명).
MLflow — KIE (LayoutLM) 성능 추적
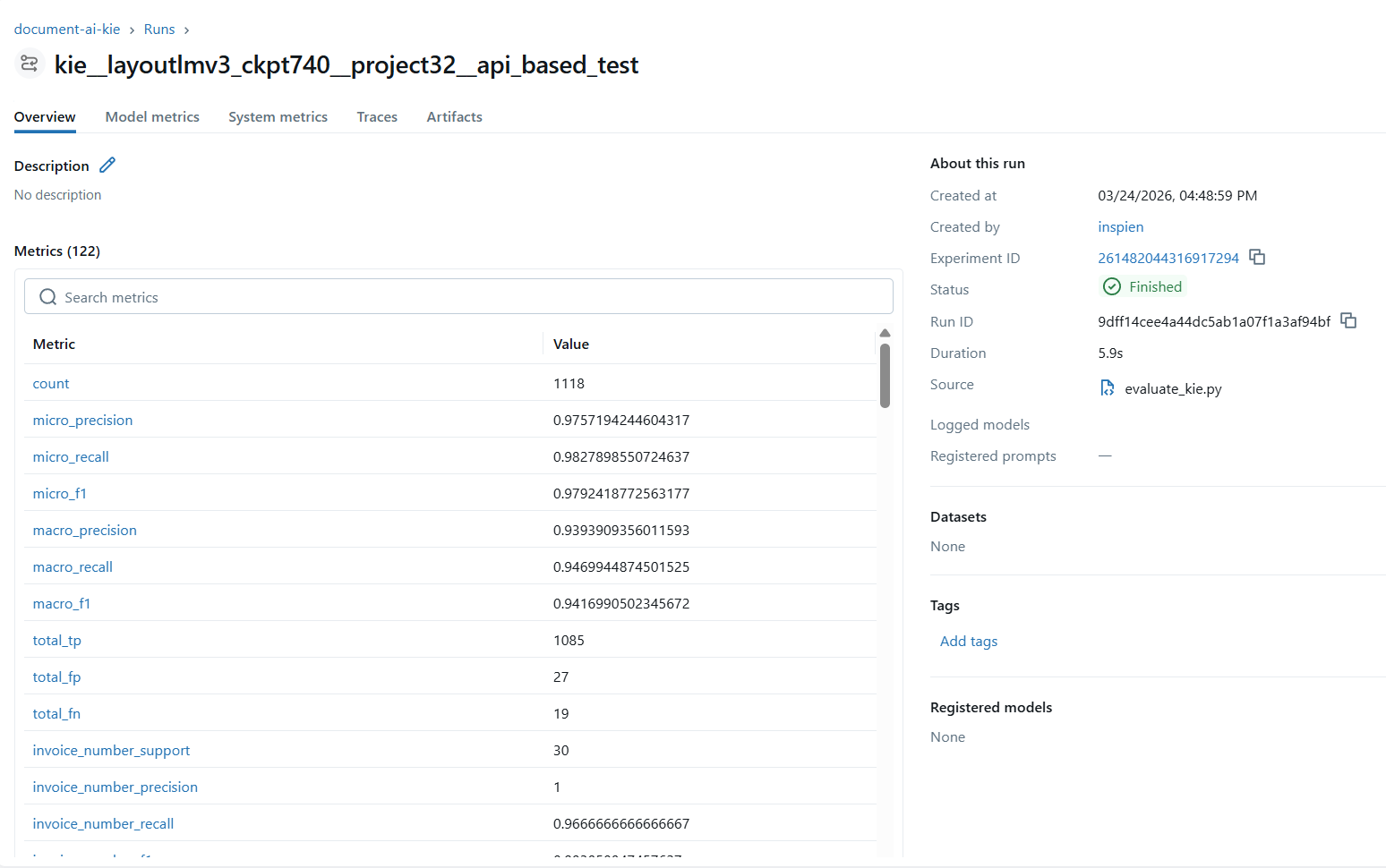
LayoutLM KIE 성능 추적 — Precision/Recall/F1
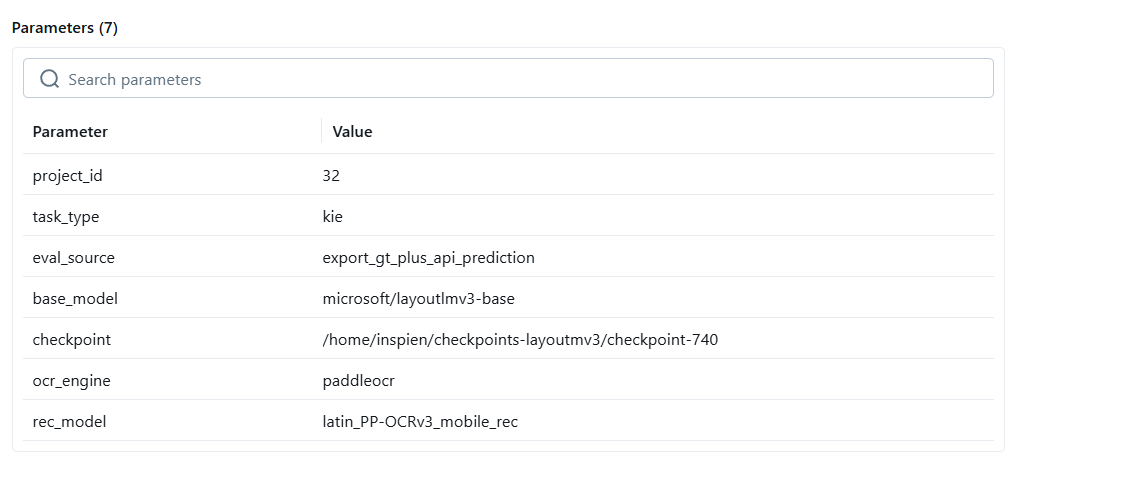
LayoutLM KIE 라벨별 성능 상세
성능 측정 결과 (Classification Report)
각 체크포인트별 Precision, Recall, F1-Score, Support 등 상세 분류 리포트. 라벨별 성능을 확인하여 모델의 강점과 개선 포인트를 파악.
성능 측정 결과 표 1 — Precision, Recall, F1-Score, Support
성능 측정 결과 표 2 — 라벨별 상세 분류 리포트
성능 측정 결과 표 3 — 추가 체크포인트 비교
성능 측정 결과 표 4 — 전체 라벨 성능 분포
성능 측정 결과 표 5 — 최종 성능 요약
MLflow 실험 추적 도입
실험 기록 자동화를 위해 MLflow Tracking Server를 구축. OCR 평가, LayoutLM 평가, End-to-End 평가를 각각 experiment로 분리하여 관리.
MLflow 서버 구성
Experiment 구조
document-ai-ocr
OCR 엔진별 CER/WER/EM 비교
run: ocr_paddle_latin_project32
document-ai-layoutlm
checkpoint별 F1/Precision/Recall
run: layoutlm_ckpt740_v1
document-ai-end2end
전체 파이프라인 성능
run: e2e_paddle_ckpt740_v1
기록 항목
Parameters
• dataset_version
• ocr_engine
• checkpoint
• num_labels
• eval_samples
Metrics
• overall_cer
• overall_wer
• overall_exact_match_rate
• eval_f1
• eval_precision
• eval_recall
• eval_accuracy
evaluate_ocr.py MLflow 연동 코드
import mlflow
from mlflow_common import setup_mlflow
# MLflow 실험 설정
setup_mlflow("document-ai-ocr")
with mlflow.start_run(run_name="ocr_paddle_latin_project32"):
mlflow.log_param("ocr_engine", "paddle_latin")
mlflow.log_param("dataset_version", "project32_v1")
# 메트릭 기록
mlflow.log_metric("overall_cer", summary["overall"]["cer"])
mlflow.log_metric("overall_wer", summary["overall"]["wer"])
mlflow.log_metric("overall_exact_match_rate", summary["overall"]["exact_match_rate"])
# 필드별 메트릭
for field, metrics in summary["field_summary"].items():
mlflow.log_metric(f"{field.lower()}_cer", metrics["cer"])
mlflow.log_metric(f"{field.lower()}_exact_match_rate", metrics["exact_match_rate"])
# Artifact 저장
mlflow.log_artifact("ocr_eval_summary.json")
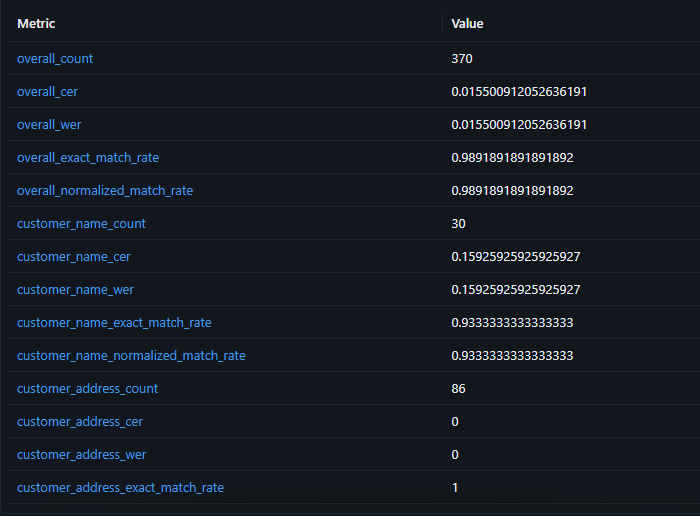
mlflow.log_artifact("ocr_eval_detailed.json")MLflow 기록 결과 (OCR 평가)
| Metric | Value |
|---|---|
| overall_count | 370 |
| overall_cer | 0.0155 |
| overall_wer | 0.0155 |
| overall_exact_match_rate | 0.9892 |
| overall_normalized_match_rate | 0.9892 |
| customer_name_cer | 0.1593 |
| customer_name_exact_match_rate | 0.9333 |
| invoice_number_exact_match_rate | 1.0 |
향후 성능 측정 계획
문서 단위 점수 (운영 KPI)
field별 가중치 정의 → 문서별 score → A/B/C/D grade → auto-pass rate 계산
bbox 품질 측정
IoU 계산, bbox match rate (IoU ≥ 0.5), text + bbox 동시 만족 계산
오답 분석 자동화
wrong cases CSV 생성, 필드별 오답 저장, error_type 분류
MLflow 코드 연결
모든 실험 param/metric/artifact 자동 기록
파이프라인 연결
OCR → LayoutLM → End-to-End 평가 완전 자동화
Summary
OCR 성능: CER 1.55%, Exact Match 98.9% (PaddleOCR, 30개 문서 기준)
KIE 성능: F1 0.9565, Precision 95.3%, Recall 96.0% (checkpoint-740)
eval_accuracy 98.8% → 토큰 단위 분류 정확도 매우 높음
MLflow Tracking Server 구축 → 실험 기록 자동화 진행 중
다중 토큰 필드(CUSTOMER_NAME 등)도 정확히 추출
업무 효율성 80% 이상 향상 (수작업 대비 처리 시간 단축)