05 / 05
튜닝
병렬 복제 워커 큐 튜닝, innodb_buffer_pool_size 최적화, 슬로우 쿼리 개선
Tuning
병렬 복제 워커 큐 튜닝
대량 Write 테스트에서 복제 지연이 발생했다. 원인을 분석해보니 워커 큐가 꽉 차서 SQL Coordinator가 멈추는 현상이었다. 워커 큐 확대와 병렬 쓰레드 증가로 해결했다.
문제 상황
Slave_SQL_Running_State: Waiting for room in worker thread event queue
SQL 스레드가 일을 더 줄 수 있는데 워커 큐가 가득 차서 못 주는 상태. Worker들이 처리 중이라 큐가 비워지지 않고 Coordinator가 큐에 못 넣는 상태다.
기존 설정값
| 변수 | 값 |
|---|---|
| slave_parallel_max_queued | 131072 (128KB) |
| slave_parallel_mode | optimistic |
| slave_parallel_threads | 2 |
| innodb_flush_log_at_trx_commit | 1 |
원인 분석
slave_parallel_max_queued는 SQL Coordinator가 워커에게 넘겨주기 위해 미리 쌓아둘 수 있는 이벤트 양이다. 이 값이 작으면 순간적인 write burst에 즉시 큐가 가득 차서 파이프라인이 멈춘다.
큐가 작을 때 (128KB)
이벤트 유입 ↑↑↑
→ Queue 128KB → 바로 FULL
→ Coordinator STOP
→ Lag 급증
큐가 클 때 (512KB)
이벤트 유입 ↑↑↑
→ Queue 512KB → 여유
→ Coordinator 계속 동작
→ Lag 완만 또는 흡수
해결
1. 워커 큐 확대
메모리 여유(7.5G 중 available 3.0G)가 있어서 큐를 4배로 확대. 추가 메모리 약 0.4MB.
SET GLOBAL slave_parallel_max_queued = 524288; -- 128KB → 512KB
2. 워커 수 증가
워커 수를 늘려서 큐에 쌓인 이벤트를 더 빨리 소비할 수 있게 했다.
SET GLOBAL slave_parallel_threads = 4; -- 2 → 4
튜닝 결과
동일한 10만건 INSERT를 다시 실행해서 비교했다.
| 항목 | 튜닝 전 | 튜닝 후 |
|---|---|---|
| 최대 Seconds_Behind_Master | ~45초 | ~12초 |
| 복구 시간 | ~3분 | ~50초 |
| Worker Queue Full | 다수 발생 | 없음 |
| 복제 지연 감소율 | - | 73% 감소 |
테스트 진행 과정
운영 적용 전에 테스트 환경에서 동일 조건으로 튜닝 효과를 검증했다.
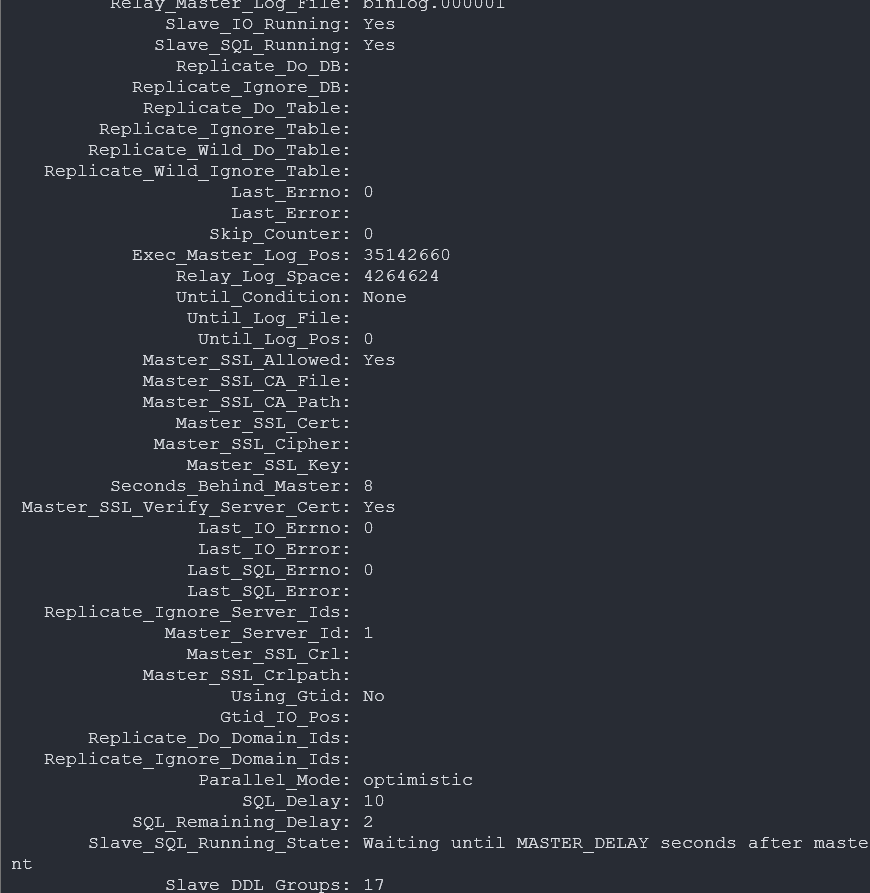
튜닝 전 부하 테스트
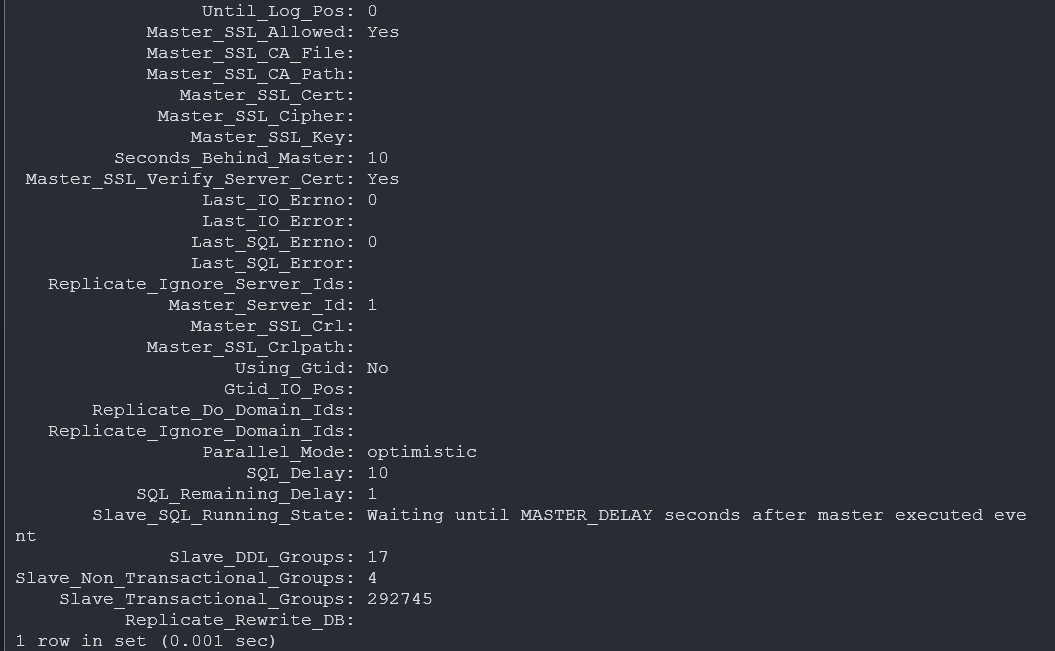
튜닝 후 결과
운영 적용
-- 1. 큐 사이즈 확대 (동적 변경) SET GLOBAL slave_parallel_max_queued = 524288; -- 2. 복제 중지 STOP SLAVE; -- 3. 워커 수 변경 SET GLOBAL slave_parallel_threads = 4; -- 4. 복제 재시작 START SLAVE; -- 5. 상태 확인 SHOW SLAVE STATUS\G
최종 설정값
| 변수 | 값 |
|---|---|
| slave_parallel_threads | 4 |
| slave_parallel_max_queued | 524288 (512KB) |
| slave_parallel_mode | optimistic |
| innodb_buffer_pool_size | 8G (PRD) |