MariaDB 복제 환경에서 Replica의 SQL 적용이 밀리면서 Seconds behind Master가 증가하는 현상이 발생했습니다.
이 글에서는 병렬 복제 워커 큐가 꽉 차서 발생한 복제 지연 문제의 원인 분석과 해결 과정을 정리합니다.
현재 복제 구조
MariaDB 병렬 복제는 다음과 같은 파이프라인으로 동작합니다.
[ IO Thread ]
↓
[ Relay Log ]
↓
[ SQL Coordinator Thread ] ← 1개
↓ (작업 분배)
[ Worker Thread 1 ] ← 실제 SQL 실행
[ Worker Thread 2 ]
[ Worker Thread 3 ] ...
각 구성 요소의 역할은 다음과 같습니다.
- IO Thread: Source(Master)에 접속해서 binlog 이벤트를 읽어서 relay log 파일로 저장하는 역할
- Coordinator: relay log를 읽고, 어떤 이벤트를 어떤 워커에게 줄지 판단
- Worker: 실제로 INSERT / UPDATE / DELETE를 실행
- Relay Log: Replica가 Master의 binlog를 받아서 자기 디스크에 저장해 둔 복제 전용 로그
Relay Log를 중간에 두는 이유
1. Master와 Replica 속도 분리 (버퍼 역할)
Master에서 계속 binlog를 생성하고 Replica SQL thread는 apply가 느려질 수 있습니다. relay log가 없다면 Master → Replica SQL 직접 연결되고, SQL이 느리면 Master 전송도 막힙니다.
relay log가 있으면 IO thread는 빠르게 받아서 디스크에 쌓고, SQL thread는 자기 속도대로 처리할 수 있습니다.
2. 장애 복구/재시작 가능
Replica mysqld가 재시작되면 이미 받아둔 relay log를 다시 읽어서 중간부터 이어서 적용할 수 있습니다. relay log가 없으면 Master에 다시 요청해야 하고 위치가 꼬이면 위험합니다.
3. 병렬 복제 구조의 핵심 자료
병렬 복제에서 SQL coordinator는 relay log를 읽어서 이벤트 단위로 쪼개서 워커에게 분배합니다. relay log 없으면 병렬 분배 자체가 불가능합니다.
문제 상황
다음과 같은 상태가 확인되었고, Seconds behind Master 지연이 발생했습니다.
Slave_SQL_Running_State: Waiting for room in worker thread event queue
이 에러의 의미는 SQL 스레드가 일을 더 줄 수 있는데 워커 큐가 가득 차서 못 주는 상태입니다. Worker들이 처리 중이라 큐가 비워지지 않고 Coordinator가 큐에 못 넣는 상태입니다.
- IO 스레드: binlog 잘 읽어옴 (
Slave_IO_Running: Yes) - SQL coordinator: 워커들에게 작업을 분배하려 함 (
Slave_SQL_Running: Yes) - 워커 큐가 꽉 차서 더 못 넣음 → 전체 파이프라인이 멈칫
현재 상황 점검
SHOW VARIABLES LIKE 'slave_parallel%';
SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit';
SHOW VARIABLES LIKE 'sync_binlog';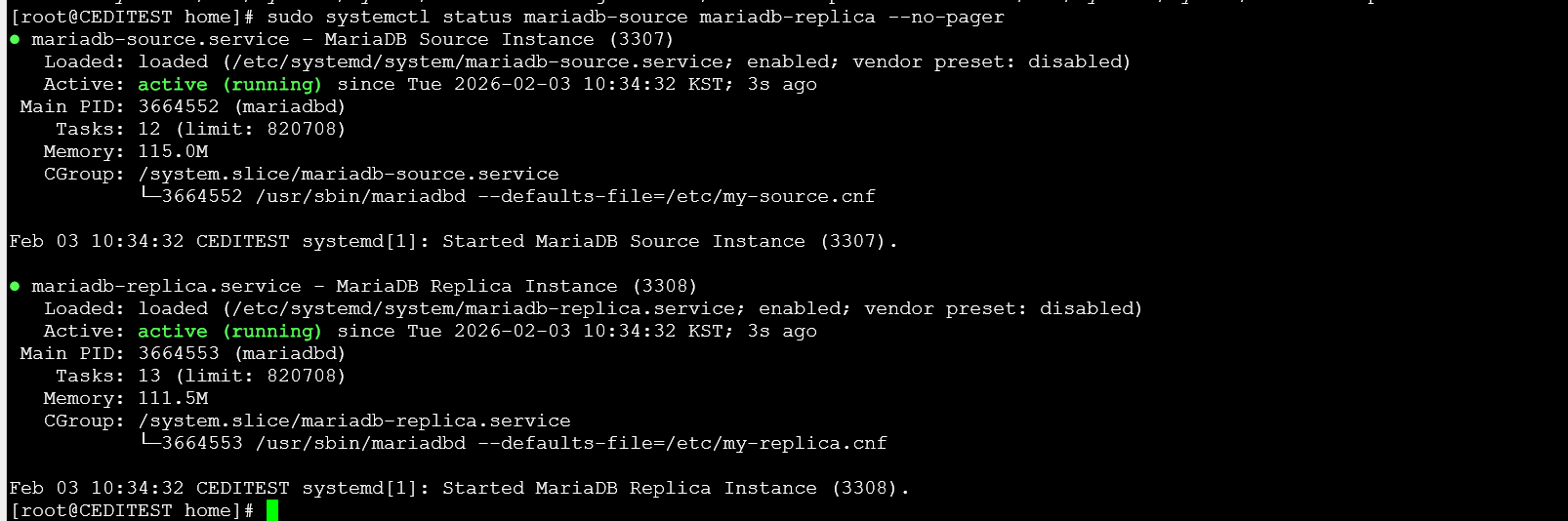
확인된 설정값:
| 변수 | 값 |
|---|---|
| slave_parallel_max_queued | 131072 |
| slave_parallel_mode | optimistic |
| slave_parallel_threads | 2 |
| slave_parallel_workers | 2 |
| innodb_flush_log_at_trx_commit | 1 |
| sync_binlog | 1 |
📌
slave_parallel_threads는 SQL을 실제로 실행하는 워커 쓰레드를 최대 몇 개까지 만들 것인가를 설정하는 값이고,slave_parallel_workers는 현재 MariaDB가 실제로 사용 중인 워커 수(상태값)로 직접 설정하는 값이 아니라 내부적으로slave_parallel_threads를 기준으로 계산됩니다.
원인 분석
slave_parallel_max_queued는 SQL coordinator가 워커에게 넘겨주기 위해 미리 쌓아둘 수 있는 이벤트 양입니다.
현재 값이 131072 (128KB)로 설정되어 있었는데, 이 값이 작으면:
- 순간적으로 write가 몰릴 때 (write burst)
- 워커가 잠깐 느려지면
- → 즉시 큐 full → SQL thread 대기 → lag 증가
운영 장애 시 서버 자원 사용률은 정상 범위였기 때문에, 원인은 인프라가 아닌 MariaDB 복제 내부 파이프라인 설정 문제로 판단했습니다.
큐가 작을 때 vs 큐가 클 때
큐가 작을 때 (128KB): 큐가 클 때 (512KB):
이벤트 유입 ↑↑↑ 이벤트 유입 ↑↑↑
↓ ↓
[ Queue 128KB ] → 바로 FULL [ Queue 512KB ]
↓ ↓
Coordinator STOP Coordinator 계속 동작
↓ ↓
Worker 천천히 처리 Worker 뒤에서 처리
↓ ↓
Lag 급증 Lag 완만 증가 또는 흡수
| 항목 | 큐 작음 | 큐 큼 |
|---|---|---|
| Coordinator | 자주 멈춤 | 거의 안 멈춤 |
| Lag 패턴 | 계단식 급증 | 완만 |
| Burst 흡수 | 못함 | 가능 |
| 처리량 | 동일 | 동일 |
Coordinator가 멈추면 lag가 더 심하게 튀는 이유
Coordinator가 정상일 때는 relay log에서 읽은 이벤트를 미리 큐에 채워 워커들이 쉬지 않고 계속 가져가게 합니다. 약간의 burst가 와도 큐가 완충 역할을 합니다.
Coordinator가 멈추면 워커들은 "지금 큐에 들어있는 것"만 처리하고 큐가 비워질 때까지 추가 공급이 중단됩니다. 그 사이 IO Thread는 계속 relay log를 쌓기 때문에 lag가 급격히 증가합니다.
해결법
1. 워커 큐 확대
메모리 상태(7.5G 중 used 3.9G, available 3.0G, buff/cache 2.8G)가 여유가 있는 편이라, 복제 큐(slave_parallel_max_queued)를 키우는 것이 부담 없었습니다.
현재 131072 → 524288 (4배)로 변경 (+0.4MB 정도)
SET GLOBAL slave_parallel_max_queued = 524288;기대 효과:
Waiting for room in worker thread event queue빈도 감소- burst성 write 들어와도 apply 파이프라인이 덜 막힘
2. 워커 수를 4로 증가
SET GLOBAL slave_parallel_threads = 4;워커 수를 늘리면 Replica의 적용 처리량(Apply Throughput)이 증가하고 더 많은 트랜잭션을 실행할 수 있습니다. 큐에 쌓인 이벤트를 더 빨리 소비할 수 있게 됩니다.
테스트 진행 과정
운영에 바로 적용하기 전에, 동일 조건의 테스트 환경에서 큐·워커 튜닝 효과를 먼저 검증했습니다.
테스트 환경 설정
기존 설정(slave_parallel_threads=2, slave_parallel_max_queued=131072)에서 write burst를 발생시켜 복제 지연을 재현한 뒤, 튜닝 후 동일 부하를 다시 걸어서 비교했습니다.
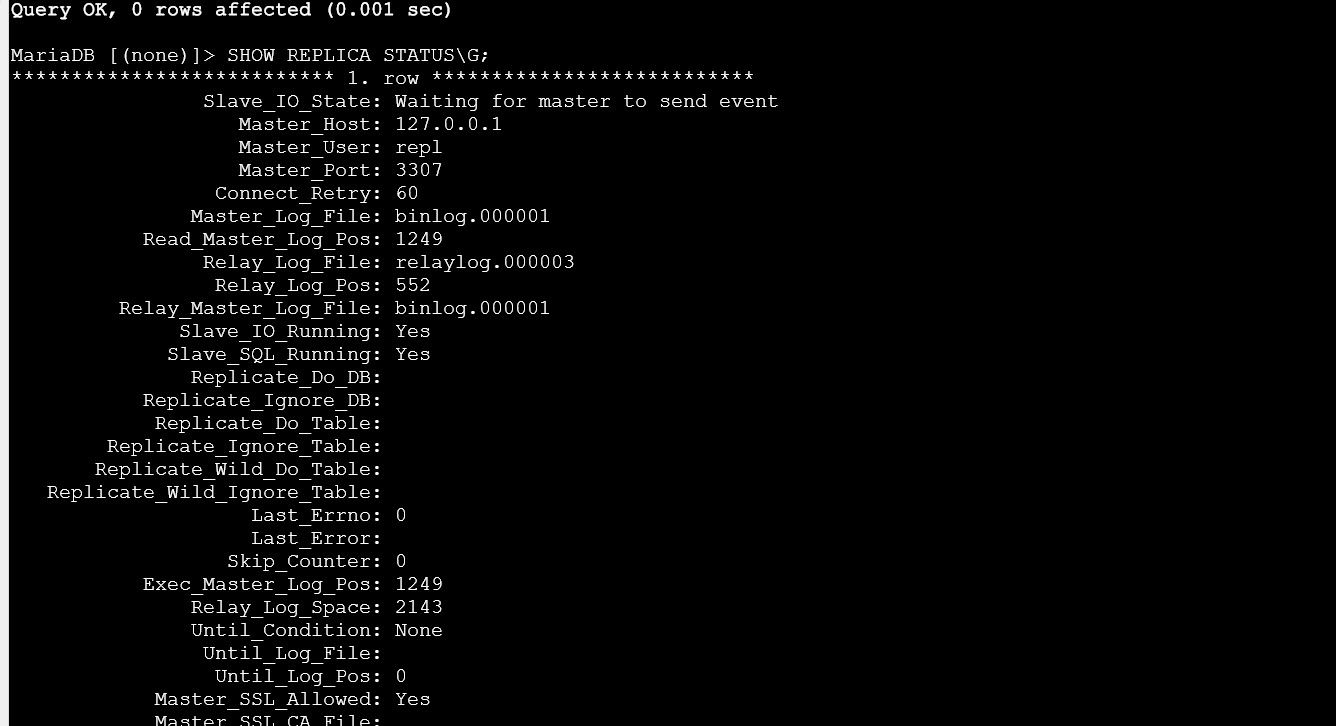
튜닝 전 부하 테스트
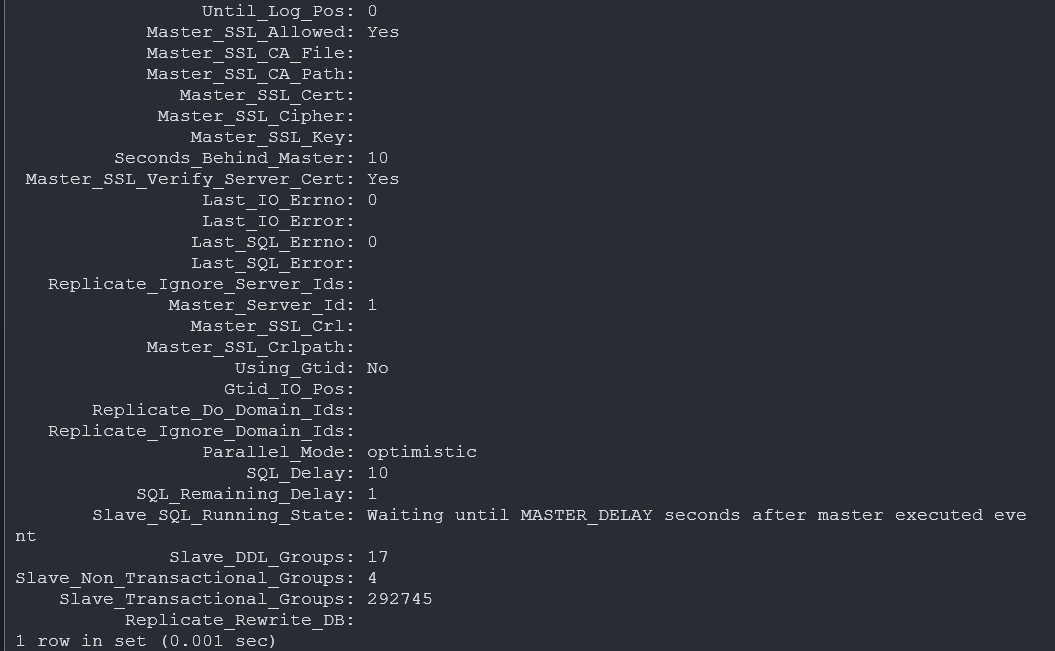
튜닝 전 상태에서 대량 write를 발생시키자 Waiting for room in worker thread event queue 상태가 반복적으로 나타나고, Seconds_Behind_Master가 급격히 증가했습니다.
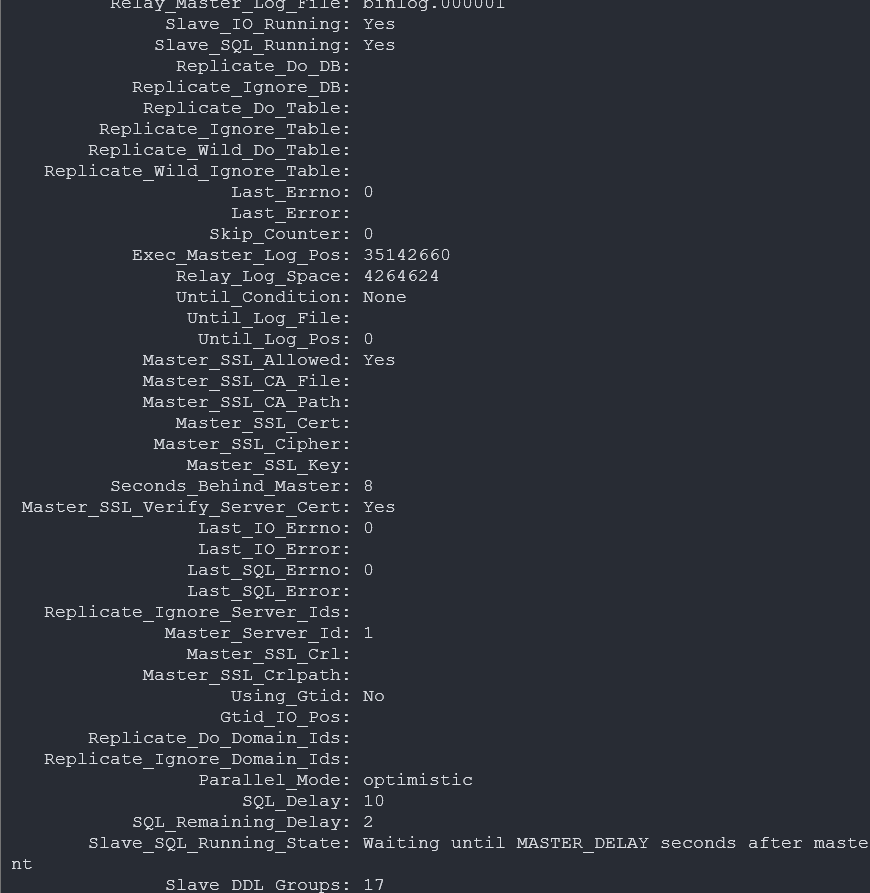
튜닝 적용
SET GLOBAL slave_parallel_max_queued = 524288;
SET GLOBAL slave_parallel_threads = 4;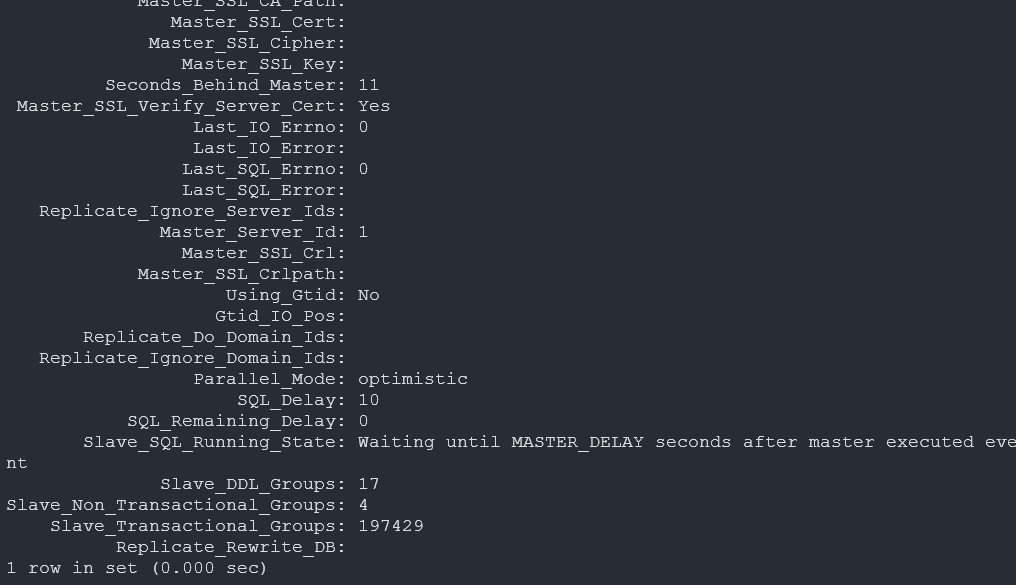
튜닝 후 부하 테스트
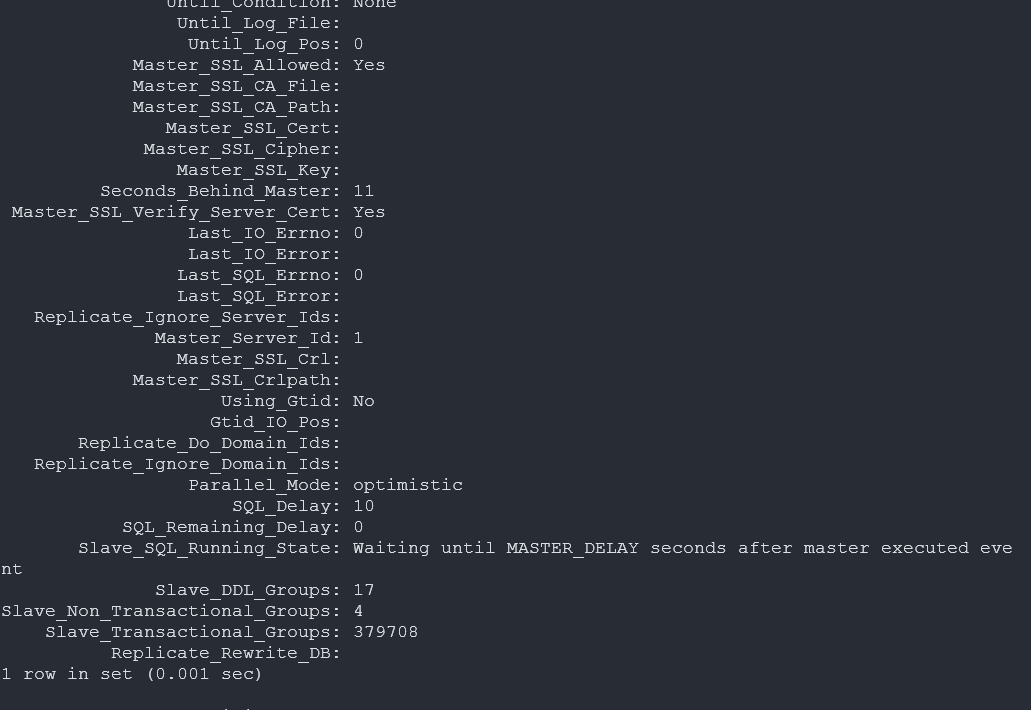
동일한 write 부하를 다시 걸었을 때, 워커 큐 full 현상이 사라지고 복제 지연이 크게 줄어든 것을 확인했습니다.
실제 적용 과정 (운영)
테스트에서 효과를 확인한 뒤 운영 환경에 적용했습니다.
slave_parallel_threads를 변경하려면 복제를 잠시 멈춰야 하는데, slave_parallel_max_queued는 동적으로 변경 가능합니다. 운영 적용 순서는 다음과 같았습니다.
-- 1. 먼저 큐 사이즈 확대 (동적 변경, 복제 중단 불필요)
SET GLOBAL slave_parallel_max_queued = 524288;
-- 2. 복제 중지
STOP SLAVE;
-- 3. 워커 수 변경
SET GLOBAL slave_parallel_threads = 4;
-- 4. 복제 재시작
START SLAVE;
-- 5. 상태 확인
SHOW SLAVE STATUS\G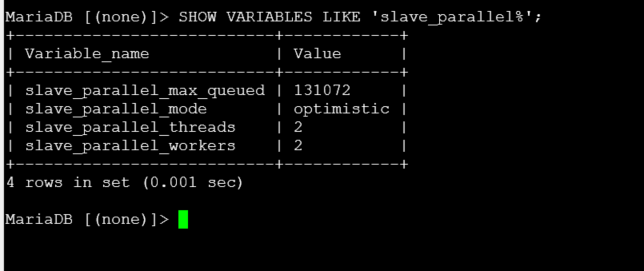
적용 후 Slave_IO_Running: Yes, Slave_SQL_Running: Yes 확인하고, Seconds_Behind_Master가 0으로 수렴하는 것까지 모니터링했습니다.
마무리
이번 문제는 서버 자원(CPU/메모리)은 정상이었지만 MariaDB 복제 내부 파이프라인 설정이 write burst를 감당하지 못해 발생한 케이스였습니다.
동일 조건에서 큐·워커 튜닝만으로 지연이 개선됨을 테스트로 확인한 뒤 운영에 적용했습니다.