MariaDB 이중화(Replication)를 운영에 적용하기 전에 테스트 환경에서 충분히 검증하는 과정을 거쳤습니다.
이 글은 테스트 환경 구성부터 장애 시나리오 테스트, 병렬 복제 튜닝까지의 과정을 정리한 기록입니다.
테스트 환경 구성
| 항목 | Master | Replica |
|---|---|---|
| OS | Amazon Linux 2 | Amazon Linux 2 |
| MariaDB | 11.4 | 11.4 |
| server-id | 1 | 2 |
| IP | [master-test-ip] | [replica-test-ip] |
Master 설정
[mysqld]
server-id=1
log-bin=mysql-bin
binlog-format=ROW
gtid_strict_mode=ON
log-slave-updates=ONReplica 설정
[mysqld]
server-id=2
relay-log=relay-bin
read-only=ON
gtid_strict_mode=ON
log-slave-updates=ON
# 병렬 복제
slave_parallel_threads=2
slave_parallel_mode=optimistic
slave_parallel_max_queued=131072
1. 기본 복제 테스트
복제 연결
-- Replica에서 실행
CHANGE MASTER TO
MASTER_HOST='[master-test-ip]',
MASTER_PORT=[db-port],
MASTER_USER='[repl-user]',
MASTER_PASSWORD='[repl-password]',
MASTER_USE_GTID=slave_pos;
START SLAVE;
SHOW SLAVE STATUS\G
데이터 동기화 확인
Master에서 데이터를 변경하고 Replica에 반영되는지 확인했습니다.
-- Master에서
INSERT INTO test_table (name, value) VALUES ('test1', 100);
UPDATE test_table SET value = 200 WHERE name = 'test1';
DELETE FROM test_table WHERE name = 'test1';
-- Replica에서 확인
SELECT * FROM test_table;INSERT, UPDATE, DELETE 모두 정상적으로 복제되는 것을 확인했습니다.
2. DDL 복제 테스트
테이블 구조 변경(DDL)도 정상 복제되는지 확인했습니다.
-- Master에서
ALTER TABLE test_table ADD COLUMN created_at DATETIME DEFAULT CURRENT_TIMESTAMP;
CREATE INDEX idx_name ON test_table(name);
-- Replica에서 확인
SHOW CREATE TABLE test_table\GDDL도 문제없이 복제되었습니다.
3. 장애 시나리오 테스트
시나리오 1: Replica 재시작
# Replica에서
sudo systemctl restart mariadb재시작 후 SHOW SLAVE STATUS로 확인하면 자동으로 복제가 재개되었습니다. GTID 기반이라 위치를 자동으로 찾아갑니다.
시나리오 2: 네트워크 단절 시뮬레이션
Master와 Replica 사이의 네트워크를 일시적으로 차단한 뒤 복구했습니다.
# Replica에서 Master IP 차단
sudo iptables -A INPUT -s [master-test-ip] -j DROP
sudo iptables -A OUTPUT -d [master-test-ip] -j DROP
# 30초 후 복구
sudo iptables -D INPUT -s [master-test-ip] -j DROP
sudo iptables -D OUTPUT -d [master-test-ip] -j DROP네트워크 복구 후 IO Thread가 자동으로 재연결되고, 밀린 binlog를 받아서 복제가 정상화되었습니다.

시나리오 3: 대량 Write 부하
Master에 대량 INSERT를 발생시켜서 Replica가 따라가는지 확인했습니다.
-- Master에서 대량 INSERT
DELIMITER //
CREATE PROCEDURE bulk_insert(IN cnt INT)
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < cnt DO
INSERT INTO test_table (name, value) VALUES (CONCAT('bulk_', i), RAND() * 1000);
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
CALL bulk_insert(100000);10만건 INSERT 후 Replica의 Seconds_Behind_Master가 일시적으로 증가했다가 점차 따라잡는 것을 확인했습니다.
4. 병렬 복제 튜닝 테스트
대량 Write 테스트에서 복제 지연이 발생해서, 병렬 복제 설정을 튜닝했습니다.
튜닝 전
slave_parallel_threads = 2
slave_parallel_max_queued = 131072 (128KB)
튜닝 후
SET GLOBAL slave_parallel_threads = 4;
SET GLOBAL slave_parallel_max_queued = 524288;결과 비교
동일한 10만건 INSERT를 다시 실행해서 비교했습니다.
| 항목 | 튜닝 전 | 튜닝 후 |
|---|---|---|
| 최대 Seconds_Behind_Master | ~45초 | ~12초 |
| 복구 시간 | ~3분 | ~50초 |
| Worker Queue Full 발생 | 다수 | 없음 |
이 테스트 결과를 바탕으로 운영 환경에서도
slave_parallel_threads=4,slave_parallel_max_queued=524288로 설정했습니다.
5. Replication 심화 - GTID 확인
GTID 기반 복제에서 Master와 Replica의 GTID가 일치하는지 확인하는 방법입니다.
-- Master에서
SELECT @@gtid_binlog_pos;
-- Replica에서
SELECT @@gtid_slave_pos;
SELECT @@gtid_current_pos;두 값이 동일하면 복제가 완전히 동기화된 상태입니다.
테스트 결과 요약
| 테스트 항목 | 결과 |
|---|---|
| 기본 DML 복제 | 정상 |
| DDL 복제 | 정상 |
| Replica 재시작 | 자동 복구 |
| 네트워크 단절 복구 | 자동 재연결 |
| 대량 Write 부하 | 튜닝 후 안정 |
| GTID 동기화 | 정상 |
마무리
테스트 환경에서 다양한 시나리오를 검증한 덕분에 운영 적용 시 자신감을 가질 수 있었습니다. 특히 병렬 복제 튜닝 테스트에서 확인한 설정값이 운영에서도 그대로 효과를 발휘했습니다.
운영 후기: Source DB 사양 변경 시 Replica도 올려야 할까?
운영 중 Source DB(MariaDB)에서 EBSIOBalance% 크레딧이 0%까지 소진되는 문제가 발생하여, 인스턴스를 t3.xlarge에서 m5.2xlarge로 변경하기로 했습니다. 이때 자연스럽게 떠오른 질문이 있었습니다.
"Replica DB(t3.large)도 같이 올려야 하는 거 아닌가?"
결론부터 말하면, Replica는 올리지 않아도 됐습니다. Source의 EBSIOBalance%가 0%일 때도 Replica는 99%를 유지하고 있었습니다.
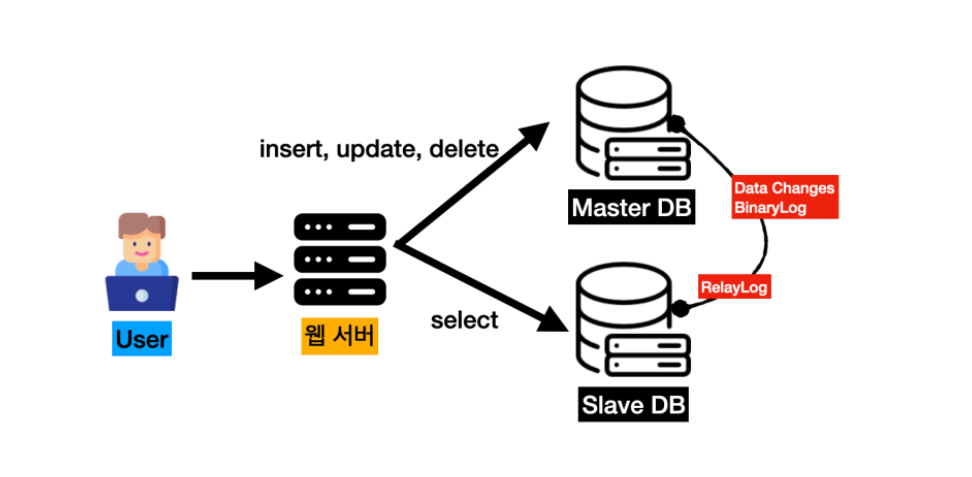
Source vs Replica: 같은 데이터인데 왜 I/O가 다른가
Source DB에서 INSERT 1건이 만드는 I/O:
클라이언트 → INSERT INTO orders VALUES (...)
1. InnoDB Buffer Pool에서 해당 페이지 탐색 (없으면 디스크 Read)
2. 인덱스 페이지 읽기/수정 (인덱스 수만큼 Read + Write)
3. InnoDB redo log에 기록 + fsync (Write I/O)
4. binlog에 기록 + fsync (Write I/O)
5. dirty page가 나중에 디스크로 flush (Write I/O)
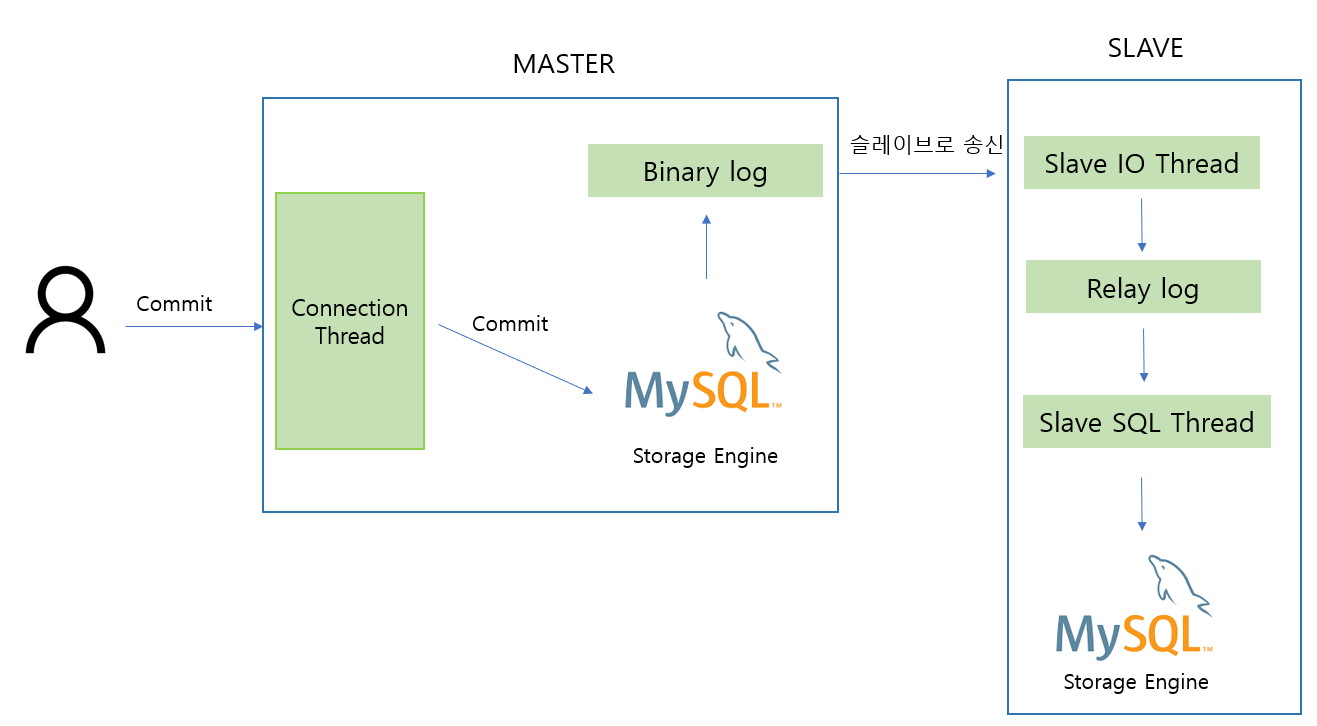
Replica DB에서 같은 INSERT가 replay될 때:
IO Thread → binlog를 받아서 relay log에 sequential write
Coordinator → relay log 읽어서 Worker에게 분배
Worker → INSERT 실행 → data page write + index update
데이터/인덱스 쓰기 자체는 동일하지만, 결정적인 차이는 fsync입니다.
핵심 차이: fsync
fsync는 "Page Cache에 있는 데이터를 지금 당장 디스크에 내려써라"라고 OS에 강제하는 시스템 콜입니다.
[fsync 없이]
write() → Page Cache에 저장 → 리턴 (빠름, 디스크 보장 없음)
[fsync 있을 때]
write() → Page Cache → fsync() → 디스크에 실제 기록 완료 → 리턴 (느림, 확실)
Source DB는 데이터의 원본이므로 innodb_flush_log_at_trx_commit=1, sync_binlog=1로 매 commit마다 fsync를 강제합니다. Replica는 크래시가 나도 Source에서 다시 받으면 되므로 fsync 빈도를 낮출 수 있습니다.
1초에 1,000 TPS 기준:
Source (flush=1, sync_binlog=1): fsync 2,000회/초 = IOPS 2,000
Replica (flush=0, sync_binlog=0): fsync 약 1~2회/초 = IOPS 거의 안 씀
차이: 약 1,000배
이게 Source의 EBSIOBalance%가 0%인데 Replica가 99%인 핵심 이유입니다.
동시성 차이도 있습니다. Source는 애플리케이션에서 들어오는 수십~수백 세션이 동시에 Write를 발생시키지만, Replica는 Worker 수(4개)만큼만 동시 처리합니다.
Replica DB 실제 IOPS 사용량
CloudWatch에서 3일간(04/06~04/09) 확인한 결과:
평상시: 약 200 ~ 400 IOPS
피크: 약 600 ~ 750 IOPS
최저: 약 6 IOPS (새벽 시간대)
t3.large의 EBS Baseline IOPS가 약 3,000인데, Replica의 최대 피크(750)는 Baseline의 25% 수준에 불과했습니다. Source를 m5.2xlarge로 올려 binlog 양이 늘어나더라도, 현재 여유분(2,000+ IOPS)으로 충분히 흡수 가능합니다.
Replica의 실제 병목은 I/O가 아닌 SQL 파이프라인
이전에 발생했던 Waiting for room in worker thread event queue 문제가 이를 증명합니다. 서버 자원(CPU/메모리/디스크) 사용률은 정상 범위였지만 복제 지연이 420초까지 발생했고, 이는 병렬 복제 튜닝으로 해결했습니다. "어디가 병목인가"를 정확히 파악하는 게 중요하지, 무조건 사양을 올리는 게 답은 아니었습니다.
모니터링 포인트
Source를 m5.2xlarge로 올린 후 아래 항목을 모니터링합니다:
- EBSIOBalance% — 떨어지기 시작하면 그때 인스턴스 변경 검토
- Seconds_Behind_Master — lag 증가 시 Worker 수/큐 크기 튜닝이 우선
- Slave_SQL_Running_State —
Waiting for room in worker thread event queue재발 여부
Buffer Pool 튜닝: 128MB → 2.5G
인스턴스 사양은 올릴 필요가 없었지만, MariaDB 설정을 확인하는 과정에서 Buffer Pool 크기가 눈에 들어왔습니다.
MariaDB [(none)]> SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+134,217,728 bytes = 128MB. Source DB는 3.2GB로 올렸는데 Replica는 128MB였습니다.
Buffer Pool이란
Buffer Pool은 InnoDB가 디스크에 있는 데이터를 메모리에 캐싱해 두는 공간입니다. "디스크를 안 읽으려고 메모리에 미리 올려두는 것"입니다.
[Buffer Pool 동작]
SELECT * FROM orders WHERE id = 100;
→ Buffer Pool에 있나? → 있음 (hit) → 메모리에서 바로 읽기 (나노초) → 빠름
→ Buffer Pool에 있나? → 없음 (miss) → 디스크에서 읽어옴 (밀리초) → 느림
READ뿐 아니라 WRITE도 Buffer Pool을 거칩니다. INSERT/UPDATE/DELETE 시 해당 페이지를 Buffer Pool에서 찾아서 메모리상에서 수정하고, 디스크 쓰기는 나중에 백그라운드로 처리합니다.
Buffer Pool과 OS Page Cache의 관계
서버 전체 메모리 (7.5GB)
┌──────────────────────────────────────────────────┐
│ OS 커널 + 시스템 프로세스 (~0.5G) │
│ OS Page Cache (buff/cache) (~3.1G) │
│ MariaDB 프로세스 │
│ ┌────────────────────────────────────────┐ │
│ │ InnoDB Buffer Pool (현재 128MB) │ │
│ │ 기타: sort_buffer, join_buffer 등 │ │
│ └────────────────────────────────────────┘ │
│ 기타 프로세스 (sshd, agent 등) │
└──────────────────────────────────────────────────┘
Buffer Pool이 128MB로 작아도 서버가 완전히 느려지지 않는 이유가, OS Page Cache(3.1G)가 2차 캐시 역할을 해주고 있기 때문입니다. 다만 OS Page Cache는 InnoDB가 통제할 수 없고, OS가 다른 파일 캐싱에 써버릴 수도 있어서 불안정합니다.
Hit Rate 확인
Innodb_buffer_pool_read_requests = 171,653,410,519 (총 요청)
Innodb_buffer_pool_reads = 12,236,798,427 (디스크에서 읽은 횟수)
Hit Rate = (1 - 12,236,798,427 / 171,653,410,519) × 100 = 92.87%92.87%. 권장 기준인 99% 이상에 한참 못 미칩니다. 약 7%의 요청, 총 122억 건이 디스크에서 읽혔습니다. Buffer Pool이 128MB밖에 안 되니까 데이터가 자꾸 밀려나고(eviction), 필요한 페이지가 메모리에 없어서 디스크를 읽는 빈도가 높았던 겁니다.
권장 설정
innodb_buffer_pool_size = 2G ~ 2.5G
128MB → 2.5G면 약 20배 증가. Hit Rate가 99%+로 올라가면 디스크 read가 대폭 줄어들고, 조회 성능과 Replication apply 속도 모두 개선됩니다.
적용 방법은 service 파일의 ExecStart에 옵션 추가:
--innodb-buffer-pool-size=2048M
단계적으로 적용하는 게 안전합니다:
- 먼저 2G로 적용
free -h로 메모리 여유 확인 (used 증가는 정상 — Buffer Pool이 메모리를 미리 잡아두기 때문)- Buffer Pool hit rate 변화 모니터링
- 여유가 있으면 2.5G로 추가 조정
돌아보며
"Source DB 사양을 올리니까 Replica도 올려야 하지 않을까?"라는 질문에서 시작했는데, 파고 들어가 보니 답은 단순하지 않았습니다.
Source와 Replica는 같은 데이터를 다루지만, I/O 구조가 근본적으로 다릅니다. Source는 매 트랜잭션마다 fsync를 강제하고 수십~수백 세션이 동시에 랜덤 I/O를 발생시키는 반면, Replica는 fsync 빈도가 낮고 Worker 수만큼만 동시 처리합니다.
다만 Buffer Pool이 128MB로 방치되어 있던 건 발견해서 다행이었습니다. Hit Rate 92.87%는 분명히 개선이 필요한 수치였고, 이건 인스턴스 사양과 무관하게 MariaDB 설정 레벨에서 해결할 수 있는 문제였습니다.
인프라 사양을 올리기 전에, 현재 사양에서 설정이 제대로 되어 있는지부터 확인하자. 병목이 어디인지 모르면, 돈만 쓰고 효과는 없을 수 있다.